RL_speeches
Reward is All you need?
Several speeches regarding reinforcement learning.
Speech_1: TURING AWARD WINNER Richard S. Sutton in Conversation with Cam Linke | No Authorities in Science
Turing award, wow!
About RL
The essence of Reinforcement Learning is learning from experiences, which differs from current large language models mimic people. Learning from experience is the obvious way to learn, thus this is the first principle of reinforcement learning.
The basic learning is learning from rewards and penalties, like interacting the world gives you instructive feedback.
How to be through keeping focus on what you believe is right
Let’s make it a field!
The process of AI is a marathon, we still have far to go the greatest impactful aspects of AI.
To be ambitious, rather arrogant. Despite the different perspectives, stay humble enough to support each other. There is no one who can just say well this is the direction for AI!
This is an introduction of RL! (Partly a celebrity speech, rather than a lecture or something academically.) Just wait for the contents below!
Speech_2: About Policy gradient
Excerpted from the reinforcement learning lecture at Shanghai Jiao Tong University.
In reinforcement learning (RL), a policy defines the probability of taking action () in state () given parameters (). The goal is to maximize the expected cumulative reward.
Objective Function
The objective function we want to maximize is the expected return:
where () is a trajectory (sequence of states and actions), and () is the total reward obtained from trajectory ().
Gradient Calculation
According to the policy gradient theorem, the gradient of the objective function can be expressed as:
This indicates that we can update the policy parameters by weighting the gradient of the log-probability of actions taken by the total reward.
Using gradient ascent, we update the parameters as follows:
where () is the learning rate.
Comparison Between Reinforcement Learning and Supervised Learning
Powered by GPT, but I think it truly make sense.
1. Objective
-
Reinforcement Learning: The objective is to learn a policy that maximizes cumulative rewards through interaction with the environment. The agent learns through trial and error, and rewards can be sparse and delayed.
-
Supervised Learning: The objective is to learn a mapping function from inputs to outputs by minimizing the error between predicted values and true labels. The data is labeled, and the learning process relies on these labels.
2. Data Handling
-
Reinforcement Learning: Data is generated through interactions with the environment. The agent selects actions at each time step and observes the results. The data is dynamic and may be influenced by changes in the policy.
-
Supervised Learning: Data is static, typically obtained from a fixed dataset. The model learns from these fixed input-output pairs during training.
3. Feedback Mechanism
-
Reinforcement Learning: Feedback is provided through reward signals, which may be delayed. The agent must explore to discover which actions are effective.
-
Supervised Learning: Feedback is direct, with the model receiving explicit label information during each training iteration, and the learning process is based on these labels.
4. Mathematical Principles
-
Reinforcement Learning: It uses Markov Decision Processes (MDPs) to model the environment. Policy gradient methods optimize expected returns and involve concepts from stochastic processes and dynamic programming.
-
Supervised Learning: It typically uses a loss function (e.g., mean squared error, cross-entropy) to measure model performance and employs optimization algorithms like gradient descent to update model parameters, involving statistical learning and optimization theory.
- 数据是交互出来的
- 每个数据具有“强化”和“弱化”的规定
强化学习的历史
从游戏AI到强化学习
强化学习 + 深度神经网络
模仿学习
- 数据并非由策略本身交互出来的
- 本质上还是大数据量的有监督学习拟合
- 学习的关键是和环境的交互!
- Offline RL 是专家数据集的交互,与传统神经网络的拟合存在差异
Reward is all you need
定义好奖励函数是交互的关键。
Next-token prediction: 如果大语言模型的本质还是监督学习,那模型如何实现推理能力的提升?如今Pre-training已经陷入瓶颈。强化学习是构建推理模型的有效方法之一,但RL is all you need.
强化学习和LLMs
Prompt Engineering
传统的API调用的问题?prompt的描述过于笨重,计算代价很高
- Agent的API调用 without having API descriptions
- 使用强化学习的必要性
The Bitter Lessons
- 瞄准方向很重要
Lecture_3: Classics: The Bitter Lesson
The “bitter lesson” originates from a classic 2019 article by AI pioneer Rich Sutton titled “The Bitter Lesson.” By examining the detours artificial intelligence has taken over the past few decades, he presents a core argument: for AI to achieve long-term improvement, leveraging powerful computational resources is paramount. This computational power inherently implies the use of vast amounts of training data and large models.
The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin.
The only thing that matters in the long run is the leveraging of computations. Researchers’ initial effort was directed towards utilizing human understanding (so that less search was needed) and only much later was much greater success had by embracing search and learning.
(The initial state of Scaling Law?)
The bitter lesson is based on the historical observations that 1) AI researchers have often tried to build knowledge into their agents, 2) this always helps in the short term, and is personally satisfying to the researcher, but 3) in the long run it plateaus and even inhibits further progress, and 4) breakthrough progress eventually arrives by an opposing approach based on scaling computation by search and learning. The eventual success is tinged with bitterness, and often incompletely digested, because it is success over a favored, human-centric approach.
My own inspections of this passage:
TBD
Speech_4: Jason Wei: Scaling Paradigms for Large Language Models
The original video on Youtube is here.[1]
Paradigm: Scaling RL on chain-of-thought

Speech_5: LLMs self-enhancement based on reinforcement learning
从人类抽象化的符号化表达————> 多模态大模型
The next token prediction at essence is the simulation of labeled data!
霍尔德和海因
生物智能不仅和感知相关,也和具身行为与环境交互有关!
The World Scope of Natural Language Processing
- WS 3 Multi-model
- WS 4 Interact with the environment
- WS 5 Interact with the society
The Basis of Reinforcement Learning
- Environment
- action and observation
- reward function
- 巴浦洛夫的狗(交互与奖励)
- Yann’s Cake
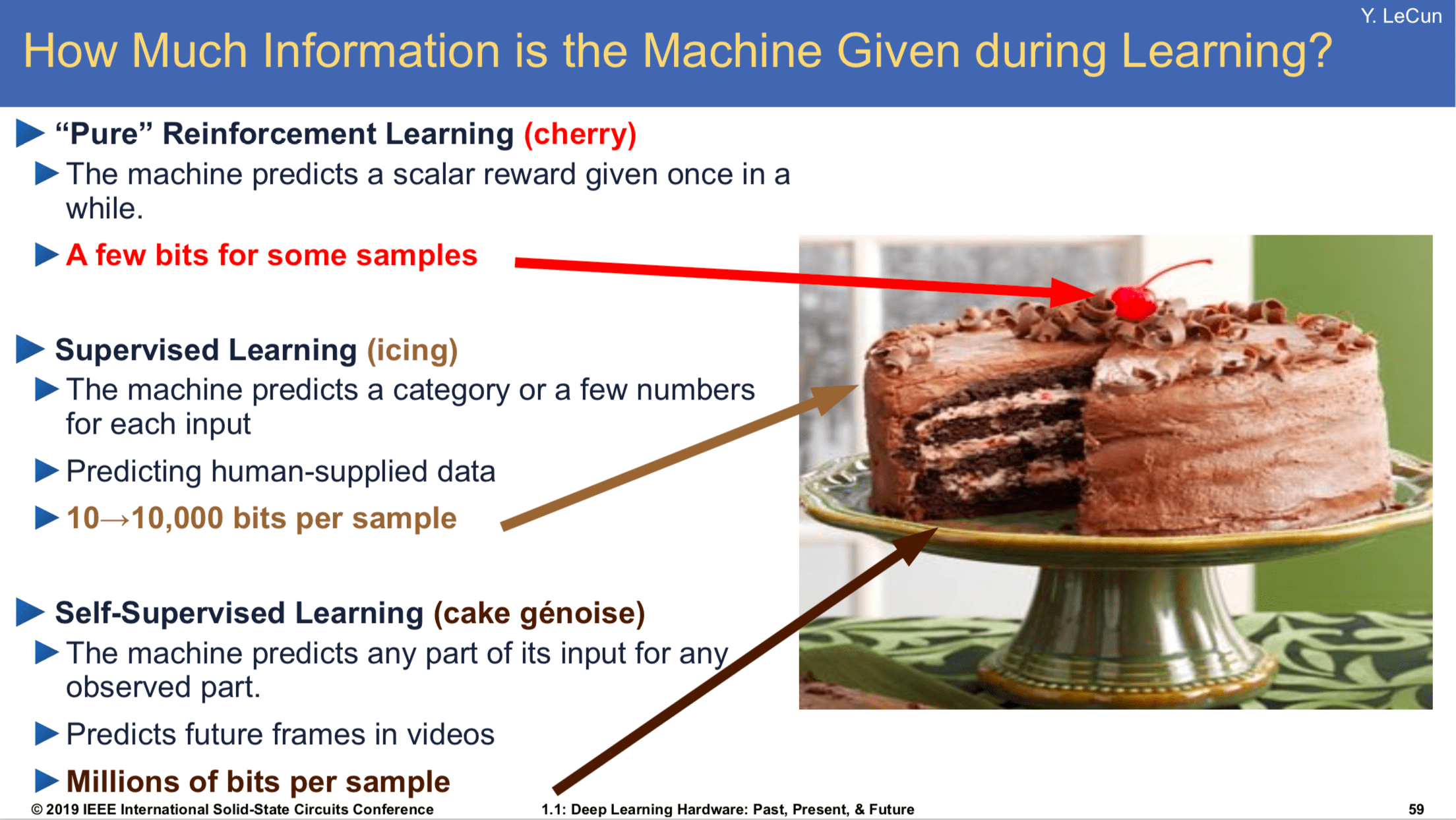
Reinforcement Learning for LLM
In early stages, reinforcement learning is for alignment and finetuning.
Policy Optimization
TBD
Several Limitations:
- The space of LLMs is huge but sparse.
- It’s time-consuming for LLMs to use Reinforcement Learning
- Limited Enhancement
LLM reasoning is all you need
We need inference models!
- OpenAI o1 illustrates that leveraging reinforcement learning explicitly incorporate reasoning steps can significantly enhance the performance.
Non-autoregressive reasoning
MDP environment is important
The bitter lesson
Reward is Enough (?)
Reward is enough to drive behavior that exhibits abilities studied in natural and AI.
Attempts
- CoT