RAG-Tutorial
Learn RAG from scratch!
Lecture Notes for This Youtube Class.[1]
Basic Knowledge
Retrieval-Augmented Generation (RAG) is a hybrid framework that combines the strengths of retrieval-based and generative models for natural language processing tasks. The basic principle of RAG involves two key components: a retriever and a generator.
The retriever is responsible for fetching relevant documents or information from a large corpus or knowledge base, typically using dense vector representations to find the most pertinent data for a given query. This ensures that the model has access to accurate, up-to-date external information beyond its training data.
The generator, usually a pre-trained language model, then uses this retrieved information to produce coherent and contextually appropriate responses. By grounding its outputs in retrieved facts, RAG reduces hallucinations and improves factual accuracy compared to purely generative models.
Basic Steps:
-
Load documents using
bs4using Crawler. -
Split text using function of
RecursiveCharacterTextSplitter()fromlangchain.text_splitter. -
Embedding splits into vectors, using
Chromafromlangchain_community.vectorstoresandOpenAIEmbeddingsand return the vector store retriever. -
Define RAG-chain (including prompt and LLM)
1
2
3
4
5
6
7# Chain
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
) -
Using the
invokefunction to get the generation text!
Query-Translation
Multi Query
Intuition: For a large problem, it is likely to encounter situations where “words fail to convey meaning,” and if the answer to the problem is relatively complex, a simple RAG system may not achieve good results through direct vector comparison. Therefore, we can decompose the problem and use parallel retrieval.
How to make the splitting works? You can use Prompt Engineering and add templates:
1 | |
In this code, we define the workchain of generate_queries, where we let OpenAI model to split question using prompts.
This is a demo of how AI generate:
1 | |
1 | |
The core chain of retrieval is retrieval_chain = generate_queries | retriever.map() | get_unique_union, where the input questions is first splitted into subquestions using genegrate_queries and through a mapping from the queries to the retriever (for every subquestion, search for the ans_vectors). Finally, using get_unique_union to get the unique answer.
1 | |
Finally, it is the RAG time! The final_rag-chain looks as follows:
1 | |
We first use retrieval_chain defined above to get the related texts in the documents, add use the itemgetter to get the original problem. Then we feed these into a LLM with the predefined prompt. Finally, we use StrOutputParser() to get the final answer of LLM.
RAG Fusions
Intuition: In Multi Query, RAG performs a crude deduplication and merging operation on the documents obtained for each subproblem, which is unreasonable because the weights corresponding to each problem are different, and the weights (similarities) of the answers obtained for each subproblem are also different. Therefore, the core idea of RAG fusion is to use a multi-retrieval fusion method based on Reciprocal Rank Fusion (RRF), calculating the corresponding weights for each document before outputting them to obtain more reasonable results.
1 | |
Decomposition
Decomposition essentially uses a simpler concatenation method to hierarchically link problems together, similar to the step-by-step reasoning in Chain of Thought (CoT). It guides the model to decompose problems through prompts and, based on the solutions to previous problems, adds new retrievals on top of the previous problem’s retrievals.
1 | |
Answer recursively
1 | |
Parallel structures are suitable for parallel problems, while hierarchical structures are appropriate for reasoning problems. It is necessary to choose the appropriate RAG architecture based on different inquiries.
Step Back
Step Back Prompting[2] is a fancy way proposed by Google DeepMind, which uses Prompt Engineering to make the Queries more abstract in order to decrease noise.
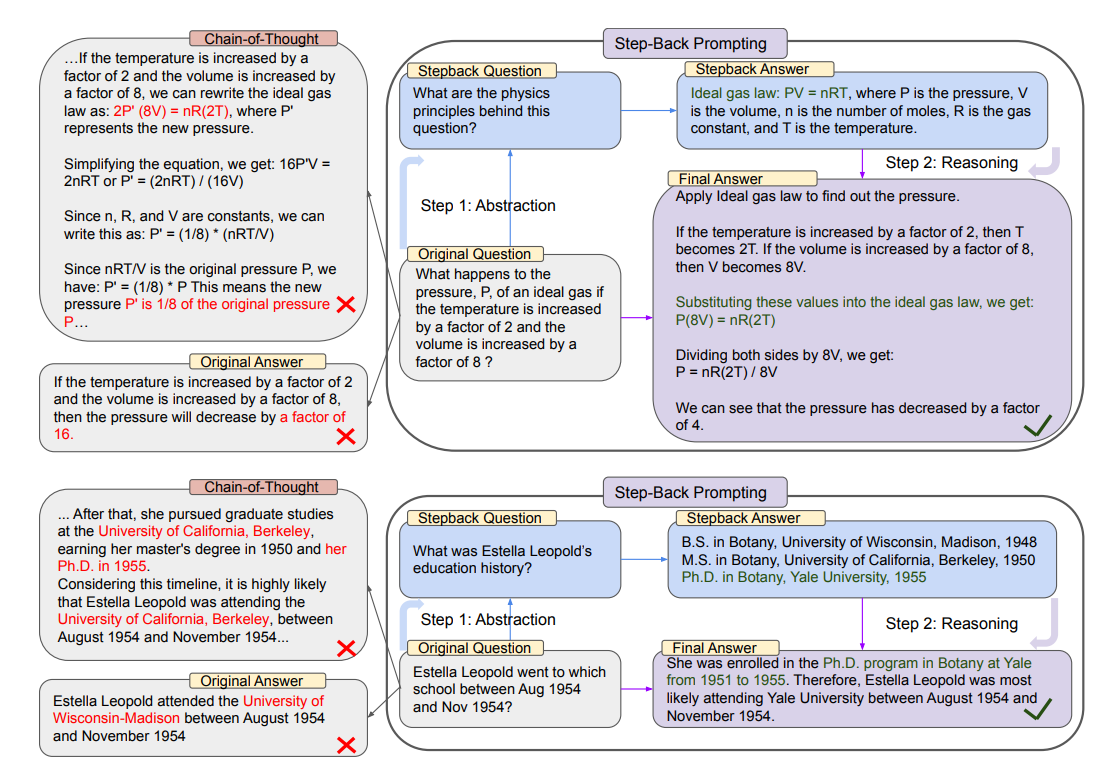
It is quite similar to Chain of Thought, but it will focus more on the abstraction process, which will distill key questions from specific contexts to achieve better results in the RAG process.
Let’s just see the prompt!
Moreover, it uses few-shot learning for learning template, which performs better than zero-shot learning.
1 | |
And for the response prompt:
1 | |
It feed AI with both the answers with normal questions and with step_back contents.
HyDE
In practical situations, questions and texts exist in two completely different spaces. Directly embedding them can lead to errors and noise interference. Therefore, we need to ensure consistency between the two spaces.
The difficulty of zero-shot dense retrieval lies precisely: it requires learning of two embedding functions (for query and document respectively) into the same embedding space where inner product captures relevance. Without relevance judgments/scores to fit, learning becomes intractable.
Let’s just see the abstract part for the passage:
Given a query, HyDE first zero-shot instructs an instruction-following language model (e.g. InstructGPT) to generate a hypothetical document. The document captures relevance patterns but is unreal and may contain false details. Then, an unsupervised contrastively learned encoder~(e.g. Contriever) encodes the document into an embedding vector. This vector identifies a neighborhood in the corpus embedding space, where similar real documents are retrieved based on vector similarity. This second step ground the generated document to the actual corpus, with the encoder’s dense bottleneck filtering out the incorrect details. Our experiments show that HyDE significantly outperforms the state-of-the-art unsupervised dense retriever Contriever and shows strong performance comparable to fine-tuned retrievers, across various tasks (e.g. web search, QA, fact verification) and languages~(e.g. sw, ko, ja).
That is what HyDE[3] for! The core idea of HyDE is to generate a hypothetical document that provides richer contextual information for the retrieval process. In HyDE, we need to generate a new hypothetical passage to simulate all possible answers.
Firstly, we need to generate a new hypothetical passage:
1 | |
1 | |
retrieval_chain = generate_docs_for_retrieval | retriever is the most fundamental part! After generating a hypothetical passage for retrieval, we then feed the answer into the retriever.
1 | |
Routing
Basic Principle: Routing the decomposed question into the right vector space.
It includes:
- Logical Routing
- Semantic Routing