''' Author: Xiyuan Yang xiyuan_yang@outlook.com Date: 2025-03-29 15:17:02 LastEditors: Xiyuan Yang xiyuan_yang@outlook.com LastEditTime: 2025-03-29 16:26:27 FilePath: /RAG_try/RAG/main.py Description: Do you code and make progress today? Copyright (c) 2025 by Xiyuan Yang, All Rights Reserved. '''
# Several Requirements import bs4 import dotenv import openai import os import streamlit as st from langchain import hub from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_community.document_loaders import WebBaseLoader from langchain_community.vectorstores import Chroma from langchain_core.output_parsers import StrOutputParser from langchain_core.runnables import RunnablePassthrough from langchain_openai import ChatOpenAI, OpenAIEmbeddings
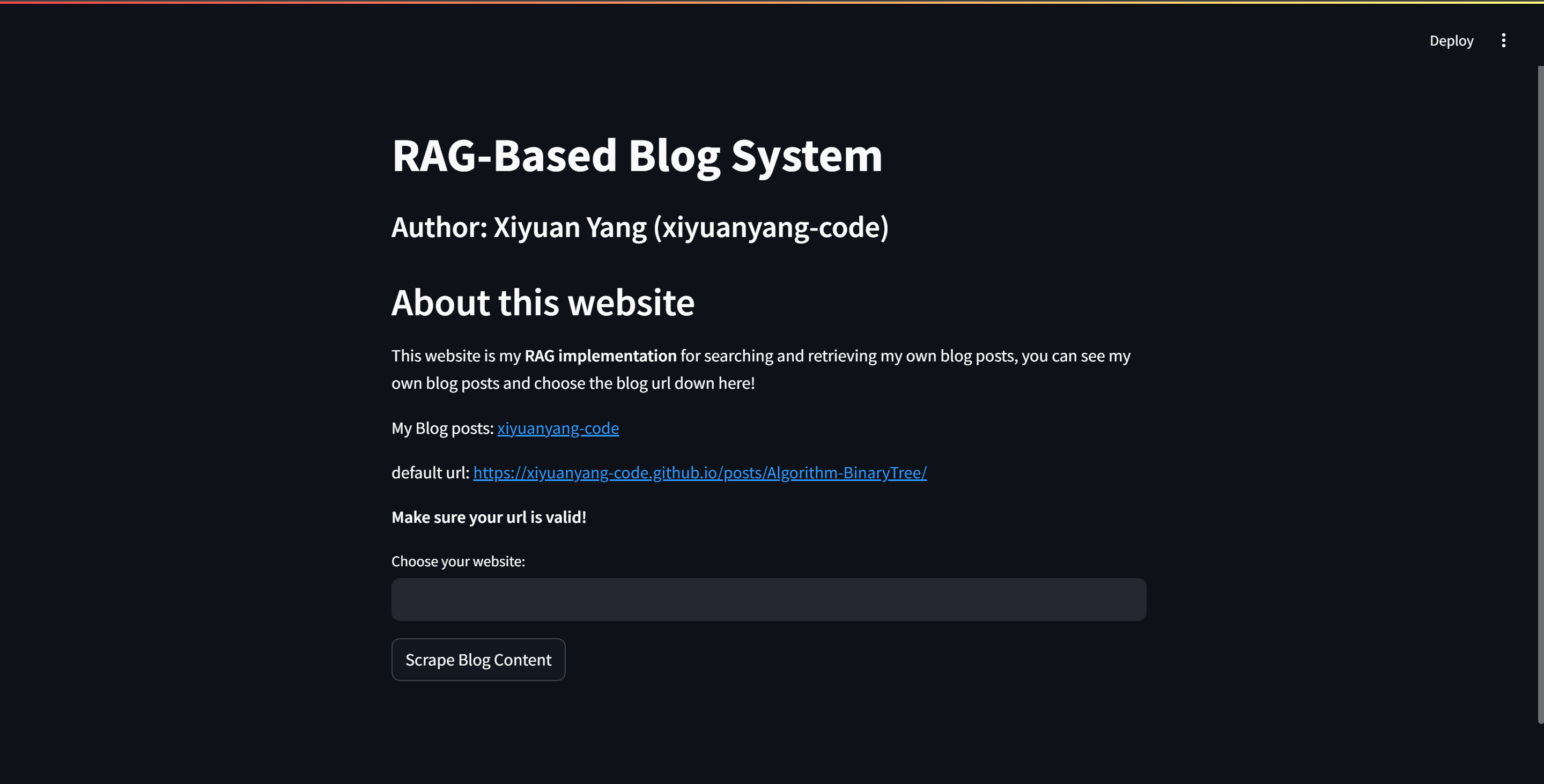
st.title("RAG-Based Blog System") st.subheader("Author: Xiyuan Yang (xiyuanyang-code)") st.session_state["Prompt"] = prompt st.session_state["LLM"] = LLM
# Introduction Part st.write("## About this website") st.write("This website is my **RAG implementation** for searching and retrieving my own blog posts, you can see my own blog posts\ and choose the blog url down here!") st.write("My Blog posts: [xiyuanyang-code](https://xiyuanyang-code.github.io)")
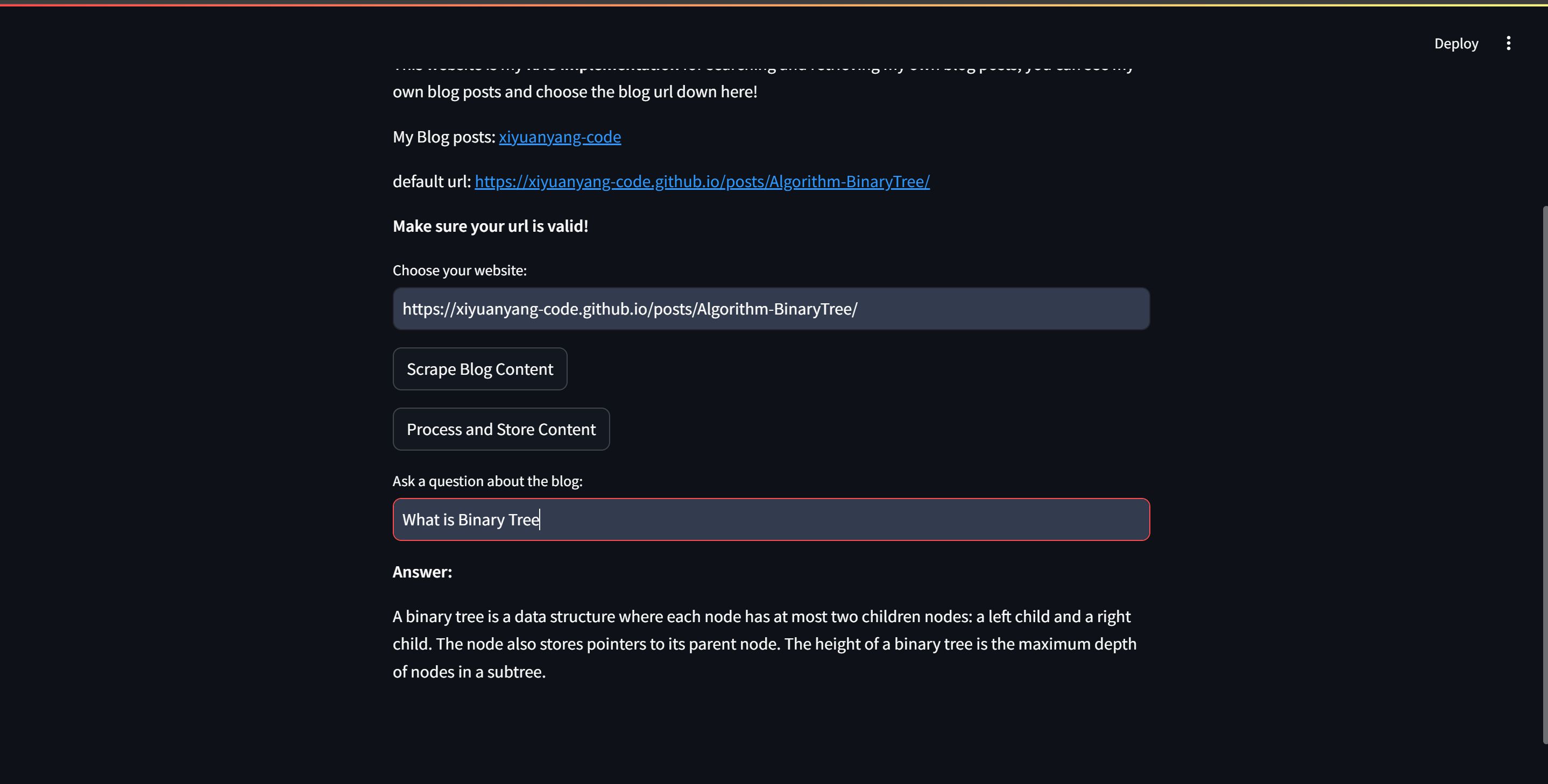
# Choose website st.write("default url: https://xiyuanyang-code.github.io/posts/Algorithm-BinaryTree/") st.write("**Make sure your url is valid!**") url = st.text_input("Choose your website: ")
default_url = "https://xiyuanyang-code.github.io/posts/Algorithm-BinaryTree/" if st.button("Scrape Blog Content"): with st.spinner("Scraping blog content..."): blog_content = loader_documents(url) if blog_content: st.success("Blog content scraped successfully!") st.session_state["blog_content"] = blog_content else: st.error("Failed to scrape blog content.",icon="🚨") st.write("Using the default url") blog_content = loader_documents(default_url)
if"blog_content"in st.session_state: blog_content = st.session_state["blog_content"] if st.button("Process and Store Content"): with st.spinner("Processing and storing content..."): splits = text_splitter(blog_content) vectorstore, retriever = embedding(splits) st.session_state["vectorstore"] = vectorstore st.session_state["retriever"] = retriever st.success("Content processed and stored in Chroma!")
query = st.text_input("Ask a question about the blog:") if query: with st.spinner("Generating answer..."): answer = get_answer(retriever=retriever, prompt=prompt, llm=LLM, question=query) st.write("**Answer:**") st.write(answer)
if __name__ == "__main__": getstreamlit_UI(prompt=prompt, LLM=LLM)
That is Python! You can use code of less than 150 lines top build a complex RAG system, generating a neat Web UI interface and implement all the needs you want! What about C++? Maybe a guessing number game…