Definition of FLOPS: a metric used to measure the computational power of a computer or processor. It indicates how many floating-point operations (calculations involving decimal numbers like addition, subtraction, multiplication, and division) a system can perform per second.
FLOPS (Ideal)=Number of Cores×Clock Frequency per Core×Floating Point Operations per cycle
FLOPS (Actual)=Execution TimesTotal Number of Floating Point Operations Performed
Memory Accounting
Tensors are the basic building block for storing everything: parameters, gradients, optimizer state, data, activations.
# torch.numel: Returns the total number of elements in the input tensor. # torch.element_size: Returns the size in bytes of an individual element.
The result shows how many bytes (1 MB = 220 bytes) a tensor is.
Basic Type
float32: 1 + 8 + 23, default type
float16: 1 + 5 + 10, cuts down the memory
bfloat16: 1 + 8 + 7.
fp8: 1 + 4 + 3 (FP8E4M3) & 1 + 5 + 2 (FP8E5M2)
Google Brain developed bfloat (brain floating point) in 2018 to address this issue. bfloat16 uses the same memory as float16 but has the same dynamic range as float32! The only catch is that the resolution is worse, but this matters less for deep learning.
# torch.numel: Returns the total number of elements in the input tensor. # torch.element_size: Returns the size in bytes of an individual element.
# for float 32 x = torch.zeros((4, 8, 20)) # @inspect x print(x.dtype) print("Number of elements in this tensor: ", x.numel()) print("The size of bytes for an individual element in this tensor: ", x.element_size()) print(get_memory_usage(x), "bytes") print(get_memory_usage(x) / 2**20)
# for empty tensor? try: empty_tensor = torch.empty(4, 8) print(get_memory_usage(empty_tensor)) except Exception as e: print(e)
# for float 16 x = torch.ones((4, 8, 20), dtype=torch.float16) print(x.dtype) print(x.numel()) print(x.element_size()) # cut the half! print(get_memory_usage(x))
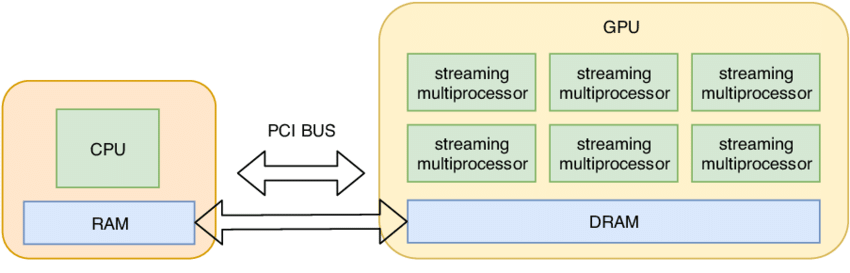
By default, tensors are stored in CPU memory. However, in order to take advantage of the massive parallelism of GPUs, we need to move them to GPU memory.
1 2 3 4 5 6 7
# basic information of GPUs num_gpus = torch.cuda.device_count() # @inspect num_gpus for i inrange(num_gpus): properties = torch.cuda.get_device_properties(i) # @inspect properties print(properties)
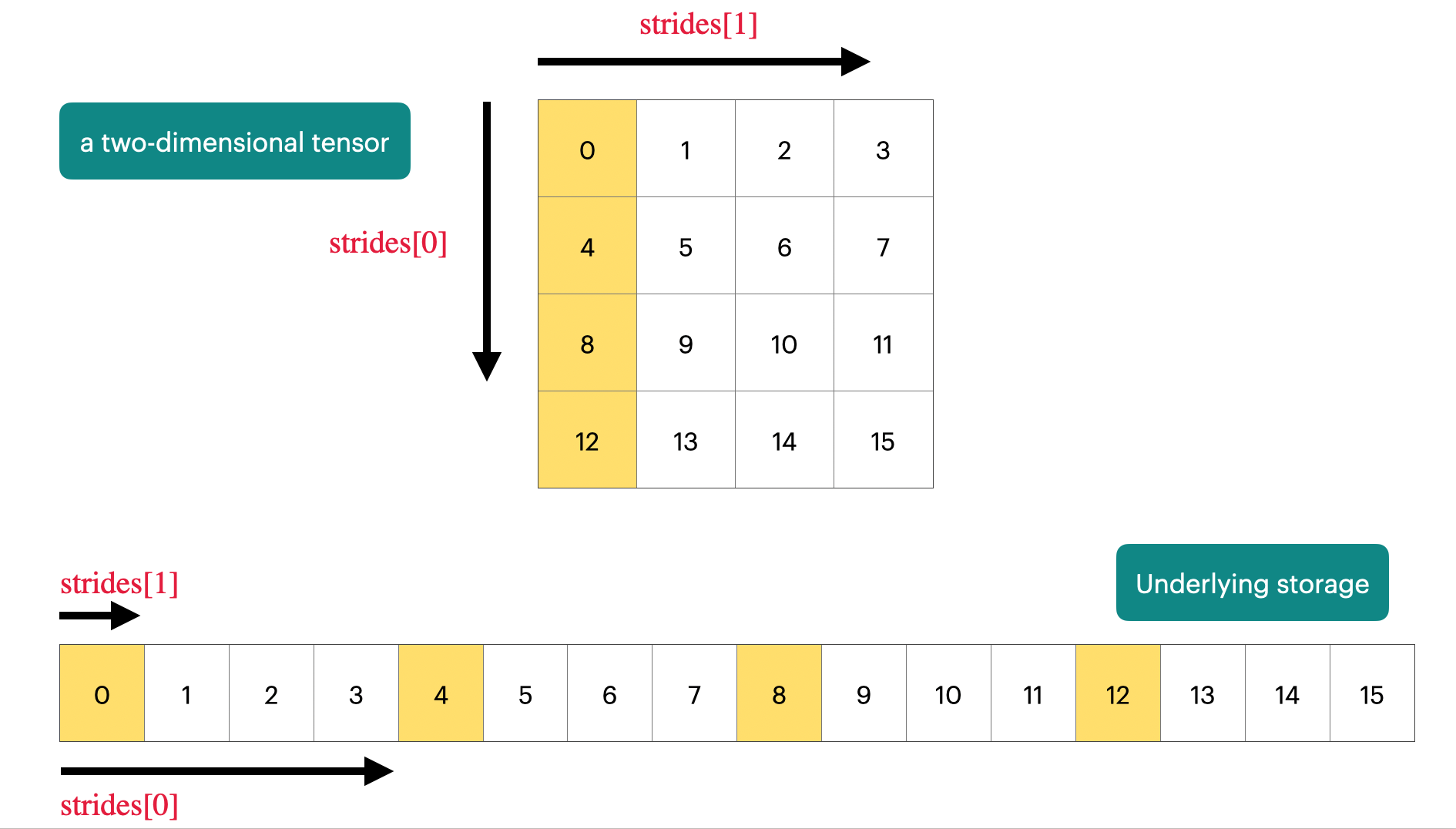
Stride is the jump necessary to go from one element to the next one in the specified dimension dim. A tuple of all strides is returned when no argument is passed in. Otherwise, an integer value is returned as the stride in the particular dimension dim.
# for the first dimension, it will jump 200 steps for reaching the next element print(test_tensor.stride(0))
# for the second dimension, it will jump 20 steps for reaching the next element print(test_tensor.stride(1))
# for the last dimension, it will jump 1 step for reaching the next element print(test_tensor.stride(-1))
print(test_tensor[2,3,4])
How it works? For example, I want to access the value of test_tensor[i,j,k]: I will move: test_tensor.stride(0) * i + test_tensor.stride(1) * j + test_tensor.stride(2) * k.
1 2 3 4 5 6 7 8 9
# other operations for tensor: slicing & element_wise # ! all the elementwise operations are operated by single element! x = torch.Tensor([3,3,4]) print(x.pow(2)) print(x.rsqrt())
# `triu` takes the upper triangular part of a matrix. test = torch.randint(1, 1000, size=(2, 2, 2)) print(test.triu())
Tensor Einops
Einops is a library for manipulating tensors where dimensions are named. It is inspired by Einstein summation notation (Einstein, 1916).
rearrange_tensor = rearrange(original_tensor, "c h w -> c w h") _to_img(rearrange_tensor, "rearrange_background")
reduce_tensor = reduce( original_tensor, "c (h h2) (w w2) -> c h w", "mean", h2=20, w2=20 ) # do average pooling (like the CNN) for given tensor print(reduce_tensor.shape) _to_img(reduce_tensor, "reduce_background")
reduce_tensor = original_tensor[1, :, :].squeeze() print(reduce_tensor.shape) repeat_tensor = repeat(reduce_tensor, "h w -> c h w", c=4) _to_img(repeat_tensor, "repeat_background")
JaxTyping
jaxtyping is a Python library that provides type annotations for your array-based code, particularly for the JAX framework. Think of it as a tool that lets you add precise shape and data type information to your function signatures, going far beyond the basic jax.Array or np.ndarray type hints.
For torch.Tensor, things get the same.
Moreover, jax support JIT and auto-grad functions.
1 2 3 4
from jaxtyping import Float x: Float[torch.Tensor, "batch seq heads hidden"] = torch.ones(2, 2, 1, 3) # @inspect x
# This will pass type checking A_good = jnp.zeros((128, 784)) B_good = jnp.zeros((784, 10)) result = matmul(A_good, B_good) print(result.shape) # (128, 10)
# A static type checker will flag an error here because "in_features" # dimensions don't match (784 vs 600). A_bad = jnp.zeros((128, 784)) B_bad = jnp.zeros((600, 10)) # result = matmul(A_bad, B_bad)
einsum
By using einops, we can run this code in a better way!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
from jaxtyping import Float from einops import einsum
# make the last dimension mean to 0 x = x - torch.mean(x, dim=-1, keepdim=True)
y = reduce(x, "... hidden -> ...", "sum") # @inspect y print(y.shape) print(y)
rearrange
Sometimes, a dimension represents two dimensions.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
x: Float[torch.Tensor, "batch seq total_hidden"] = torch.ones(2, 3, 8) # @inspect x # ...where total_hidden is a flattened representation of heads * hidden1 w: Float[torch.Tensor, "hidden1 hidden2"] = torch.ones(4, 2)
print(f"x shape: {x.shape}")
# Break up total_hidden into two dimensions (heads and hidden1): # total_hidden = hidden1 \times hidden2 x = rearrange(x, "... (heads hidden1) -> ... heads hidden1", heads=2) # @inspect x print(f"x shape: {x.shape}")
# Perform the transformation by w: x = einsum(x, w, "... hidden1, hidden1 hidden2 -> ... hidden2") # @inspect x # Combine heads and hidden2 back together: print(f"x shape: {x.shape}") x = rearrange(x, "... heads hidden2 -> ... (heads hidden2)") # @inspect x print(f"x shape: {x.shape}")
Computation Cost
Having gone through all the operations, let us examine their computational cost.
A floating-point operation (FLOP) is a basic operation like addition (x + y) or multiplication (x y).
FLOPs: floating-point operations (measure of computation done)
FLOP/s: floating-point operations per second (also written as FLOPS), which is used to measure the speed of hardware.
Several Statistics
GPT-3: 3.14e23 FLOPs
GPT-4: 2e25 FLOPS
A100 has a peak performance of 312 teraFLOP/s. (teraFLOPS = 1e12 FLOPS)
17806267 hours (total)
linear model demo
Core: Matrix Multiplications
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
if torch.cuda.is_available(): B = 16384# Number of points D = 32768# Dimension K = 8192# Number of outputs else: B = 1024 D = 256 K = 64 device = "cuda"if torch.cuda.is_available() else"cpu" x = torch.ones(B, D, device=device) w = torch.randn(D, K, device=device) y = x @ w # We have one multiplication (x[i][j] * w[j][k]) and one addition per (i, j, k) triple. actual_num_flops = 2 * B * D * K # @inspect actual_num_flops
print(actual_num_flops)
Interpretation:
B is the number of data points
(D K) is the number of parameters
FLOPs for forward pass is 2 (# tokens) (# parameters)
It turns out this generalizes to Transformers (to a first-order approximation).
Model FLOPS Utilization
MFU=promised FLOPSactual FLOPS
actual FLOPS=timesum FLOPs
promised FLOPS is provided by the hardware company.
Usually, MFU of >= 0.5 is quite good (and will be higher if matmuls dominate)
Time Complexity for Several Operations
Consider Matrix A: (m,n) and matrix B: (n,k).
FLOPs for matrix multiplications: m×n×(2k)
Elementwise operation on a m×n matrix requires O(mn) FLOPs.
Addition of two m×n matrices requires mn FLOPs.
FLOPs depends highly on hardware and data types.
Gradient Basics
Computing Gradients also need computation resources!
Consider simple linear regression model:
1 2 3 4
x = torch.tensor([1., 2, 3]) w = torch.tensor([1., 1, 1], requires_grad=True) # Want gradient pred_y = x @ w loss = 0.5 * (pred_y - 5).pow(2)
import torch if torch.cuda.is_available(): B = 16384# Number of points D = 32768# Dimension K = 8192# Number of outputs else: B = 1024 D = 256 K = 64 device = "cuda"if torch.cuda.is_available() else"cpu" x = torch.ones(B, D, device=device) w1 = torch.randn(D, D, device=device, requires_grad=True) w2 = torch.randn(D, K, device=device, requires_grad=True) # Model: x --w1--> h1 --w2--> h2 -> loss h1 = x @ w1 print(h1.shape) # (B, D) h2 = h1 @ w2 loss = h2.pow(2).mean()
# FLOPs # two layers, thus two matrix multiplications num_forward_flops = (2 * B * D * D) + (2 * B * D * K)
Question: How long would it take to train a 70B parameter model on 15T tokens on 1024 H100s? total_flops = 6 * 70e9 * 15e12 # @inspect total_flops
Models
Module Parameters
Initialization
When the input dimension input_dim of a neural network layer is large, its output values also tend to become very large.
For example, output = x @ w describes a multiplication of a vector x by a weight matrix w. If the elements of both x and w are sampled randomly from a standard normal distribution, then according to probability theory, the variance of each element in the output output is proportional to input_dim.
For example, the j-th element of output is:
outputj=i=1∑input_dimxi⋅wij
If xi and wij have a mean of 0 and a variance of 1, then the variance of outputj is:
This means the standard deviation of output is input_dim. This could cause damages when the input dim scales larger, for instance: gradient vanishing, etc.
In language modeling, data is a sequence of integers (output by the tokenizer). It is convenient to serialize them as numpy arrays (done by the tokenizer).
1 2 3 4 5 6 7 8 9 10 11 12
orig_data = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10], dtype=np.int32) orig_data.tofile("data.npy") # You can load them back as numpy arrays. # Don't want to load the entire data into memory at once (LLaMA data is 2.8TB). # Use memmap to lazily load only the accessed parts into memory. data = np.memmap("data.npy", dtype=np.int32) assert np.array_equal(data, orig_data) # A data loader generates a batch of sequences for training. B = 2# Batch size L = 4# Length of sequence x = get_batch(data, batch_size=B, sequence_length=L, device=get_device()) assert x.size() == torch.Size([B, L])
Optimizer
Let’s define the AdaGrad optimizer
momentum = SGD + exponential averaging of grad
AdaGrad = SGD + averaging by grad^2
RMSProp = AdaGrad + exponentially averaging of grad^2
Adam = RMSProp + momentum
SGD (Stochastic Gradient Descent)
This is the most basic optimization method. It updates model parameters by calculating the gradient of the loss function and moving in the opposite direction of the gradient.
wt+1=wt−η⋅gt
Where:
wt is the parameter at the current time step.
η is the learning rate, a hyperparameter that controls the step size.
gt is the gradient at the current time step.
Main Problem: The learning rate is fixed. This can cause the optimizer to move too fast in steep areas and too slow in flat areas. It also tends to oscillate in certain directions.
AdaGrad (Adaptive Gradient Algorithm)
AdaGrad is an improvement over SGD that introduces the concept of an adaptive learning rate. It uses a different learning rate for each parameter, and these rates decay over time during training.
Core Idea: It scales the learning rate for each parameter by accumulating the sum of the squares of all past gradients.
Gt=τ=1∑tgτ2
wt+1=wt−Gt+ϵη⋅gt
Where:
Gt is the sum of the squared gradients from the start of training up to the current time step.
ϵ is a small constant to prevent division by zero.
Advantage: It’s well-suited for sparse data, as parameters that are updated infrequently get a larger learning rate.
Main Problem: Since Gt is a monotonically increasing sum, the learning rate for all parameters will eventually become extremely small, halting further learning in the later stages of training.
RMSProp (Root Mean Square Propagation)
RMSProp addresses the issue of AdaGrad’s rapidly decaying learning rate. Instead of accumulating the sum of all past squared gradients, it uses an exponentially weighted moving average of the squared gradients. This allows it to “forget” distant past gradients, preventing the learning rate from decaying too quickly.
Core Idea: It replaces AdaGrad’s cumulative sum with an exponential moving average.
E[g2]t=γ⋅E[g2]t−1+(1−γ)⋅gt2
wt+1=wt−E[g2]t+ϵη⋅gt
Where:
E[g2]t is the exponentially weighted moving average of the squared gradients.
γ is a decay rate, typically set to 0.9 or 0.99.
Advantage: It solves the premature learning rate decay problem of AdaGrad, allowing the model to continue learning throughout training.
Adam (Adaptive Moment Estimation)
Adam combines the best of RMSProp and Momentum. It maintains an exponentially weighted moving average of both the gradients (the momentum term) and the squared gradients (the RMSProp term).
Core Idea:
First moment: An exponentially weighted moving average of the gradients (the momentum term).
mt=β1mt−1+(1−β1)gt
Second moment: An exponentially weighted moving average of the squared gradients (the RMSProp term).
vt=β2vt−1+(1−β2)gt2
vt=(1−β2)i=1∑tβ2t−igi2
v represents variance. Var(g)=E[g2]−(E[g])2, and vt represents the moving average squared gradients. Thus we have: Var(g)≈vt−(mt)2vt and mt are all moving average of g2 and g, which in essence is a weighted average.
Adam also includes a bias correction, as mt and vt are biased towards zero in the initial training steps.
The final update rule after bias correction is:
m^t=1−β1tmt,v^t=1−β2tvt
wt+1=wt−v^t+ϵη⋅m^t
Advantage: It combines the benefits of momentum and adaptive learning rates, leading to faster convergence and often superior performance. Adam is a highly popular and widely used optimizer for a wide range of deep learning tasks.
Memory
1 2 3 4 5 6 7 8 9 10 11 12 13
# Parameters num_parameters = (D * D * num_layers) + D # @inspect num_parameters assert num_parameters == get_num_parameters(model) # Activations num_activations = B * D * num_layers # @inspect num_activations # Gradients num_gradients = num_parameters # @inspect num_gradients # Optimizer states num_optimizer_states = num_parameters # @inspect num_optimizer_states # For Adam, it is 2 * num_parameters
Training language models take a long time and will certainly crash. You don’t want to lose all your progress. During training, it is useful to periodically save your model and optimizer state to disk.
1 2 3 4 5 6 7 8 9 10
model = Cruncher(dim=64, num_layers=3).to(get_device()) optimizer = AdaGrad(model.parameters(), lr=0.01) # Save the checkpoint: checkpoint = { "model": model.state_dict(), "optimizer": optimizer.state_dict(), } torch.save(checkpoint, "model_checkpoint.pt") # Load the checkpoint: loaded_checkpoint = torch.load("model_checkpoint.pt")
Mixed Precision Training
Choice of data type (float32, bfloat16, fp8) have tradeoffs.
Higher precision: more accurate/stable, more memory, more compute
Lower precision: less accurate/stable, less memory, less compute
Solution: use float32 by default, but use {bfloat16, fp8} when possible. A concrete plan:
Use {bfloat16, fp8} for the forward pass (activations).
Use float32 for the rest (parameters, gradients).
Pytorch has an automatic mixed precision (AMP) library.