DataStructure-Tutorial
Data Structure Tutorial
在本文将要系统梳理之后笔者将要学习的数据结构的内容,这是笔者遇到的第一门难度较大且较为重要的专业课程,将成为笔者2025年的更新重点之一。
Before Reading
在阅读这一系列博客之前,你需要掌握以下知识:
- C++的基本语法(Necessary!)
- 面向过程
- 面向对象
- Python的基本语法(Optional)
- 掌握一些基本的关于算法的基础知识
- 递归算法
- 迭代算法
- STL的一些基本知识(会使用一些基本的接口)
References
- 入门教材:Hello 算法
- 非常经典且优质的一本教材,有在线学习的网站,并且开源了书中所有代码示例。
- 内容相对较少,但是都是基础中的基础,非常适合新手的快速入门,在一轮过后再深入学习一些更深入的知识。
- 主力教材:《数据结构:思想与实现》——翁慧玉,俞勇
- 经典教材!
- 但是教材的难度较大,是笔者下学期上课的教材,也会作为更新的重点。
- 其他参考教材:
- 图解算法(可视化做的很好)
- 《大话数据结构》
- 《数据结构和算法分析——C语言描述》
注:示例代码主要都以C++或者Python代码给出。
What’s have been updated
- 导论(在本篇发表之前已经更新)
- 数据结构和算法
- 算法的时间复杂度,空间复杂度
- 线性结构
- 线性表
- 线性表的顺序实现(数组)
- 线性表的链接实现(链表)
- 栈
- 队列
- 字符串
- 线性表
- 树状结构
- 二叉树
- 哈夫曼树
- 优先级队列
- 集合结构
- 集合与静态查找表
- 动态查找表
- 二叉查找树
- AVL树
- 红黑树
- AA树
- 伸展树
- 散列表(哈希表)
- 算法应用:排序
- 插入排序
- 选择排序
- 交换排序
- 归并排序
- 基数排序
- 外部查找和排序
- B树
- B+树
- 图状结构
- 图
- 最小生成树
- 算法应用问题:最短路径问题
- 算法设计基础
- 枚举法
- 贪婪法
- 分治法
- 动态规划
- 回溯法
- 随机算法
Introduction to Data structure
Definition
- A set of elements
- with specific relations
- the same type of data
- Logic relations and operations
Data structure, in essence, represents the abstract simulation of logic relations of different objects.
- Set relations (集合结构)
- Linear relations 1-1 (线性结构)
- Tree relations (节点一对多,树形结构)
- Graph relations (节点多对多,图结构)
The difference between these structures lie in different aspects. For instance, the time and space efficiency for traverse, insert or other basic operations of elements.
Operations are of great importance for data structure!
Physical Structure
如图 3-3 所示,物理结构反映了数据在计算机内存中的存储方式,可分为连续空间存储(数组)和分散空间存储(链表)。物理结构从底层决定了数据的访问、更新、增删等操作方法,两种物理结构在时间效率和空间效率方面呈现出互补的特点。
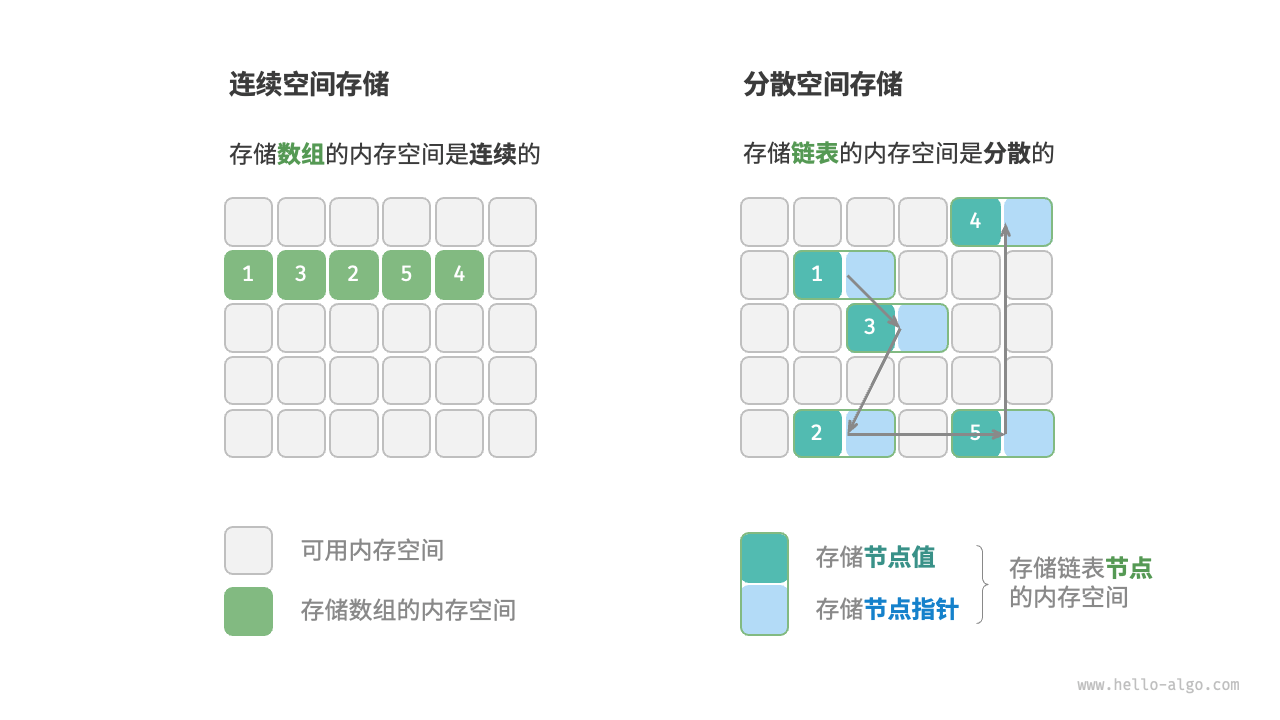
连续空间存储(数组)
- 定义:连续空间存储是指数据元素在内存中连续排列,数组是这种存储方式的典型代表。
- 优点:
- 快速访问:由于数组元素是连续存储的,可以通过索引直接访问任意元素,时间复杂度为 O(1)。
- 空间局部性:连续存储有助于缓存命中率,因为访问一个元素后,后续访问相邻元素时,可能已经在缓存中。
- 缺点:
- 插入和删除操作效率低:在数组中插入或删除元素通常需要移动其他元素以保持数据的连续性,时间复杂度为 O(n)。
- 固定大小:数组的大小在创建时确定,扩展数组的大小需要重新分配内存并复制数据。
分散空间存储(链表)
- 定义:分散空间存储是指数据元素在内存中不必连续排列,链表是这种存储方式的典型代表。
- 优点:
- 动态大小:链表可以方便地进行动态内存分配,允许在运行时灵活地增加或减少元素。
- 高效插入和删除:在链表中,插入和删除元素只需调整指针,而不需要移动其他元素,时间复杂度为 O(1)(在已知位置的情况下)。
- 缺点:
- 访问速度慢:由于链表元素存储在非连续的内存位置,访问某个特定元素需要从头遍历链表,时间复杂度为 O(n)。
- 额外空间开销:链表需要额外的存储空间来存储指针(如前驱和后继指针),这增加了内存使用量。
互补特点
- 数组适合需要频繁随机访问的场景,如需要快速读取大量数据但不经常修改数据的情况。
- 链表适合需要频繁插入和删除操作的场景,如实现动态数据结构(例如队列、栈)时。
值得说明的是,所有数据结构都是基于数组、链表或二者的组合实现的。例如,栈和队列既可以使用数组实现,也可以使用链表实现;而哈希表的实现可能同时包含数组和链表。
- 基于数组可实现:栈、队列、哈希表、树、堆、图、矩阵、张量(维度 ≥3 的数组)等。
- 基于链表可实现:栈、队列、哈希表、树、堆、图等。
哈希表底层是数组,而为了解决哈希冲突,我们可能会使用“链式地址”(后续“哈希冲突”章节会讲):数组中每个桶指向一个链表,当链表长度超过一定阈值时,又可能被转化为树(通常为红黑树)。
从存储的角度来看,哈希表的底层是数组,其中每一个桶槽位可能包含一个值,也可能包含一个链表或一棵树。因此,哈希表可能同时包含线性数据结构(数组、链表)和非线性数据结构(树)。
Storage
- Sequential Storage
- Linked Storage
The two mostly used basic storage implementation of all data-structures.
- Hash storage(散列存储/哈希存储)
- Especially for set structures
- Ideal: All nodes lies in a continuous space uniformly.
- Hash collision and Hash functions
- Index Storage (索引存储)
- All nodes will be placed in a sequential order.
- An index place to show relations of different nodes.
Introduction to Algorithm
My personal lecture notes of https://www.hello-algo.com/en/
Abstract
- 迭代与递归
- 时间复杂度
- 空间复杂度
- 数据结构的物理结构
Algorithm and complexity
由于实际测试具有较大的局限性,因此我们可以考虑仅通过一些计算来评估算法的效率。这种估算方法被称为渐近复杂度分析(asymptotic complexity analysis),简称复杂度分析。
复杂度分析能够体现算法运行所需的时间和空间资源与输入数据大小之间的关系。它描述了随着输入数据大小的增加,算法执行所需时间和空间的增长趋势。这个定义有些拗口,我们可以将其分为三个重点来理解。
- “时间和空间资源”分别对应时间复杂度(time complexity)和空间复杂度(space complexity)。
- “随着输入数据大小的增加”意味着复杂度反映了算法运行效率与输入数据体量之间的关系。
- “时间和空间的增长趋势”表示复杂度分析关注的不是运行时间或占用空间的具体值,而是时间或空间增长的“快慢”。(一种趋势!)
Iteration and Recursion
迭代:自下而上,小问题积累成大问题
递归:自上而下,大问题拆解成小问题
程序实现重复代码块执行的两种方式:
-
迭代(for循环,while循环)
-
递归
递归(recursion)是一种算法策略,通过函数调用自身来解决问题。它主要包含两个阶段。
- 递:程序不断深入地调用自身,通常传入更小或更简化的参数,直到达到“终止条件”。
- 归:触发“终止条件”后,程序从最深层的递归函数开始逐层返回,汇聚每一层的结果。
而从实现的角度看,递归代码主要包含三个要素。
- 终止条件:用于决定什么时候由“递”转“归”。
- 递归调用:对应“递”,函数调用自身,通常输入更小或更简化的参数。
- 返回结果:对应“归”,将当前递归层级的结果返回至上一层。
有关递归的时间问题和空间问题
递归函数每次调用自身时,系统都会为新开启的函数分配内存,以存储局部变量、调用地址和其他信息等。这将导致两方面的结果。
-
函数的上下文数据都存储在称为“栈帧空间”的内存区域中,直至函数返回后才会被释放。因此,递归通常比迭代更加耗费内存空间。(需要控制递归深度,否则过深的递归会导致栈的溢出错误)
-
有关栈帧空间:
-
栈帧空间是指在程序执行过程中,为每个函数调用分配的一块内存区域,用于存储该函数的局部变量、参数、返回地址以及其他控制信息。每次函数被调用时,都会在调用栈上创建一个新的栈帧,这个栈帧的生命周期与函数的执行周期相同。
- 返回地址:当函数调用完成后,程序需要知道从哪里继续执行,因此返回地址会被压入栈帧中。
- 参数:函数调用时传递给被调用函数的参数也会存储在栈帧中。
- 局部变量:函数内部定义的局部变量会占用栈帧空间。
- 控制信息:包括指向上一个栈帧的指针(帧指针),用于维护调用链。
栈帧的工作机制
- 入栈:当一个函数被调用时,首先将参数和返回地址压入栈中,然后分配空间给局部变量,形成新的栈帧。
- 出栈:当函数执行完毕时,局部变量和参数的空间被释放,返回地址被弹出,程序控制流转回调用该函数的位置。
栈帧的优点
- 自动管理:栈帧由系统自动管理,无需手动分配和释放内存。
- 高效性:由于栈的后进先出特性,内存分配和释放速度非常快。
-
递归调用函数会产生额外的开销。因此递归通常比循环的时间效率更低。
-
使用尾递归可以优化递归的效率(系统无需保存函数上一级的上下文)
有关递归树
我们在函数内递归调用了两个函数,这意味着从一个调用产生了两个调用分支。如图 2-6 所示,这样不断递归调用下去,最终将产生一棵层数为 n 的递归树(recursion tree)。
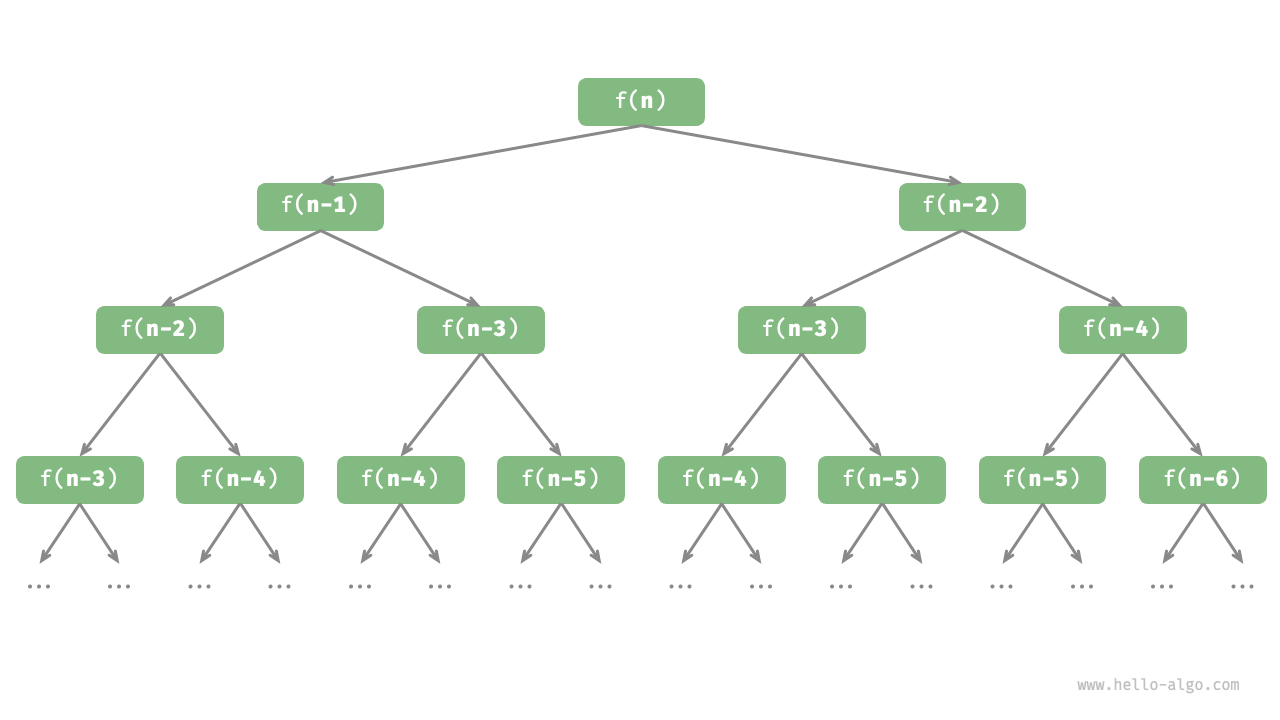
这种递归树可以达到指数阶的时间复杂度。
一定要理解递归的核心思想:分治!
从本质上看,递归体现了“将问题分解为更小子问题”的思维范式,这种分治策略至关重要。
- 从算法角度看,搜索、排序、回溯、分治、动态规划等许多重要算法策略直接或间接地应用了这种思维方式。
- 从数据结构角度看,递归天然适合处理链表、树和图的相关问题,因为它们非常适合用分治思想进行分析。
迭代和递归的本质与内在联系
以上述递归函数为例,求和操作在递归的“归”阶段进行。这意味着最初被调用的函数实际上是最后完成其求和操作的,这种工作机制与栈的“先入后出”原则异曲同工。
事实上,“调用栈”和“栈帧空间”这类递归术语已经暗示了递归与栈之间的密切关系。
- 递:当函数被调用时,系统会在“调用栈”上为该函数分配新的栈帧,用于存储函数的局部变量、参数、返回地址等数据。
- 归:当函数完成执行并返回时,对应的栈帧会被从“调用栈”上移除,恢复之前函数的执行环境。
1 | |
Time complexity
- 常数时间复杂度
- 线性时间复杂度
- 平方时间复杂度
- 指数阶时间复杂度
- 递归树的一分为二
- 对数阶时间复杂度
- 每轮缩减到一半
- 也会出现在递归树中(经典例题:快速幂计算)
- 线性对数阶时间复杂度(
O(nlogn))
1 | |
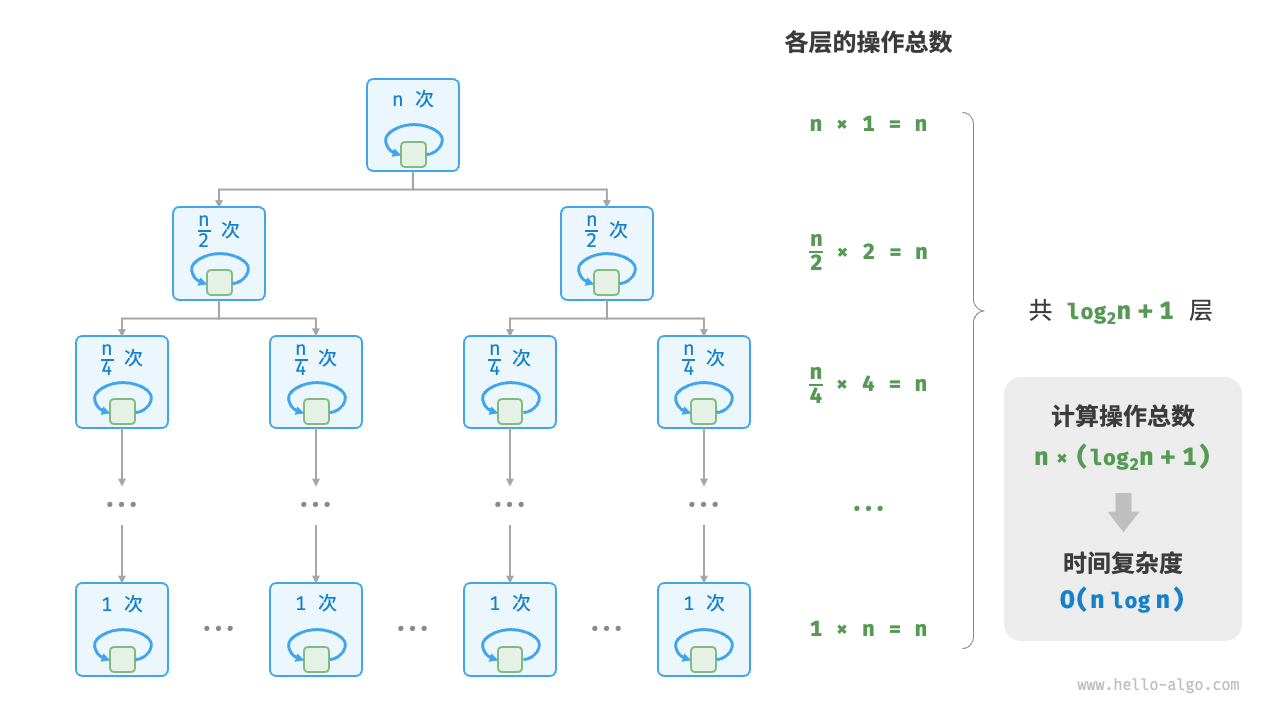
- 阶乘阶时间复杂度
1 | |
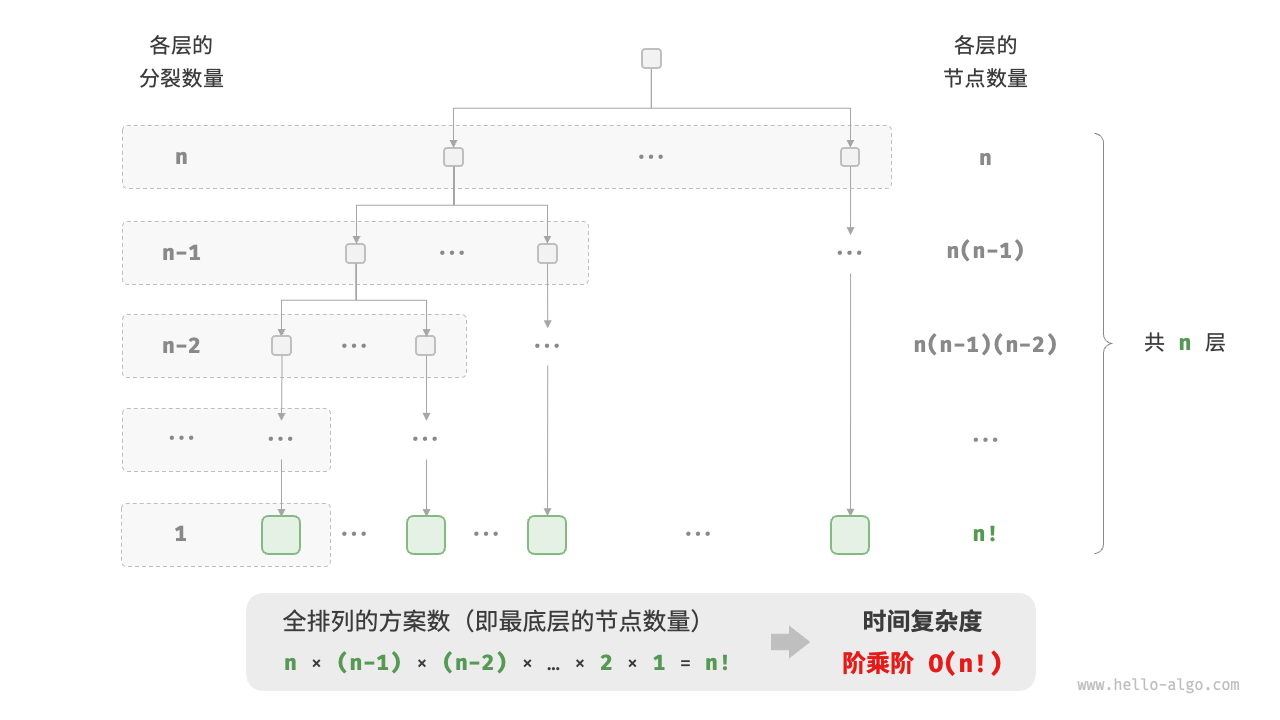
时间复杂度的分类:
- 最差时间复杂度
- 最佳时间复杂度
以上两个时间复杂度均与数据的分布存在联系,具有偶然性
- 平均时间复杂度
The essence of time complexity lies in not considering the specific runtime function, but rather focusing only on the order of the runtime function. This is because, when the data size is large, the highest-order term of the time function dominates the overall trend.
Symbolic representation of time complexity
时间复杂度的符号表示法主要有三种:O、Ω 和 Θ,它们分别表示算法在不同情况下的性能表现。
- 大 O 表示法 (O(f(n))):
- 描述:表示算法在最坏情况下的时间复杂度。
- 用途:用于描述算法的上界,即算法的执行时间不会超过某个函数的增长速度。
- 示例:如果一个算法的时间复杂度是 (O(n^2)),意味着在最坏情况下,算法的执行时间最多是输入规模的平方。
- 大 Ω 表示法 (Ω(f(n))):
- 描述:表示算法在最好情况下的时间复杂度。
- 用途:用于描述算法的下界,即算法的执行时间至少是某个函数的增长速度。
- 示例:如果一个算法的时间复杂度是 (Ω(n)),意味着在最好情况下,算法的执行时间至少是输入规模的线性增长。
- 大 Θ 表示法 (Θ(f(n))):
- 描述:表示算法在平均情况下的时间复杂度。
- 用途:用于描述算法的确界,即算法的执行时间既不会超过某个函数的上界,也不会低于某个函数的下界。
- 示例:如果一个算法的时间复杂度是 (Θ(n \log n)),意味着在所有情况下,算法的执行时间大致是输入规模的 (n \log n) 级别。
- Explanation in Maths: exits c1, c2 and N0, when N > N0, c1*F(N) <= T(n) <= c2*F(N)
- 小o表示法:
- T(N) 是 Ω(F(N)) and T(N) 不是 Θ(F(N))
Space complexity
算法在运行过程中使用的内存空间主要包括以下几种。
- 输入空间:用于存储算法的输入数据。
- 暂存空间:用于存储算法在运行过程中的变量、对象、函数上下文等数据。
- 输出空间:用于存储算法的输出数据。
一般情况下,空间复杂度的统计范围是“暂存空间”加上“输出空间”。
暂存空间可以进一步划分为三个部分。
- 暂存数据:用于保存算法运行过程中的各种常量、变量、对象等。
- 栈帧空间:用于保存调用函数的上下文数据。系统在每次调用函数时都会在栈顶部创建一个栈帧,函数返回后,栈帧空间会被释放。
- 指令空间:用于保存编译后的程序指令,在实际统计中通常忽略不计。
在分析一段程序的空间复杂度时,我们通常统计暂存数据、栈帧空间和输出数据三部分。
1 | |
而与时间复杂度不同的是,我们通常只关注最差空间复杂度。这是因为内存空间是一项硬性要求,我们必须确保在所有输入数据下都有足够的内存空间预留。
- 以最差输入数据为准
- 以算法运行的峰值内存(注意不是累积量)为准
一些常见的空间复杂度:
-
常数阶空间复杂度
- 在循环中初始化变量或调用函数而占用的内存,在进入下一循环后就会被释放,因此不会累积占用空间,空间复杂度还是
O(1)。
- 在循环中初始化变量或调用函数而占用的内存,在进入下一循环后就会被释放,因此不会累积占用空间,空间复杂度还是
-
线性阶空间复杂度
1
2
3
4
5
6
7
8def linear(n: int):
"""线性阶"""
# 长度为 n 的列表占用 O(n) 空间
nums = [0] * n
# 长度为 n 的哈希表占用 O(n) 空间
hmap = dict[int, str]()
for i in range(n):
hmap[i] = str(i)1
2
3
4
5
6
7def linear_recur(n: int):
"""线性阶(递归实现)"""
print("递归 n =", n)
if n == 1:
return
linear_recur(n - 1)
# 在达到最深的递归深度的时候,会有n个变量n(涉及到局部变量) -
平方阶空间复杂度
1
2
3
4def quadratic(n: int):
"""平方阶"""
# 二维列表占用 O(n^2) 空间
num_matrix = [[0] * n for _ in range(n)]-
num_matrix:这是一个变量名,用于存储生成的二维矩阵。[[0] * n for _ in range(n)]:这是一个列表生成式,用于创建一个包含n个子列表的列表,每个子列表包含n个元素。[0] * n:这一部分创建一个包含n个0的列表。例如,如果n是3,则生成[0, 0, 0]。for _ in range(n):这一部分用于重复创建上述的子列表n次。_是一个惯用的变量名,表示循环变量在循环体内未被使用。
1
2
3
4
5
6
7def quadratic_recur(n: int) -> int:
"""平方阶(递归实现)"""
if n <= 0:
return 0
# 数组 nums 长度为 n, n-1, ..., 2, 1
nums = [0] * n
return quadratic_recur(n - 1)
-
-
指数阶空间复杂度(二叉树)
1
2
3
4
5
6
7
8def build_tree(n: int) -> TreeNode | None:
"""指数阶(建立满二叉树)"""
if n == 0:
return None
root = TreeNode(0)
root.left = build_tree(n - 1)
root.right = build_tree(n - 1)
return root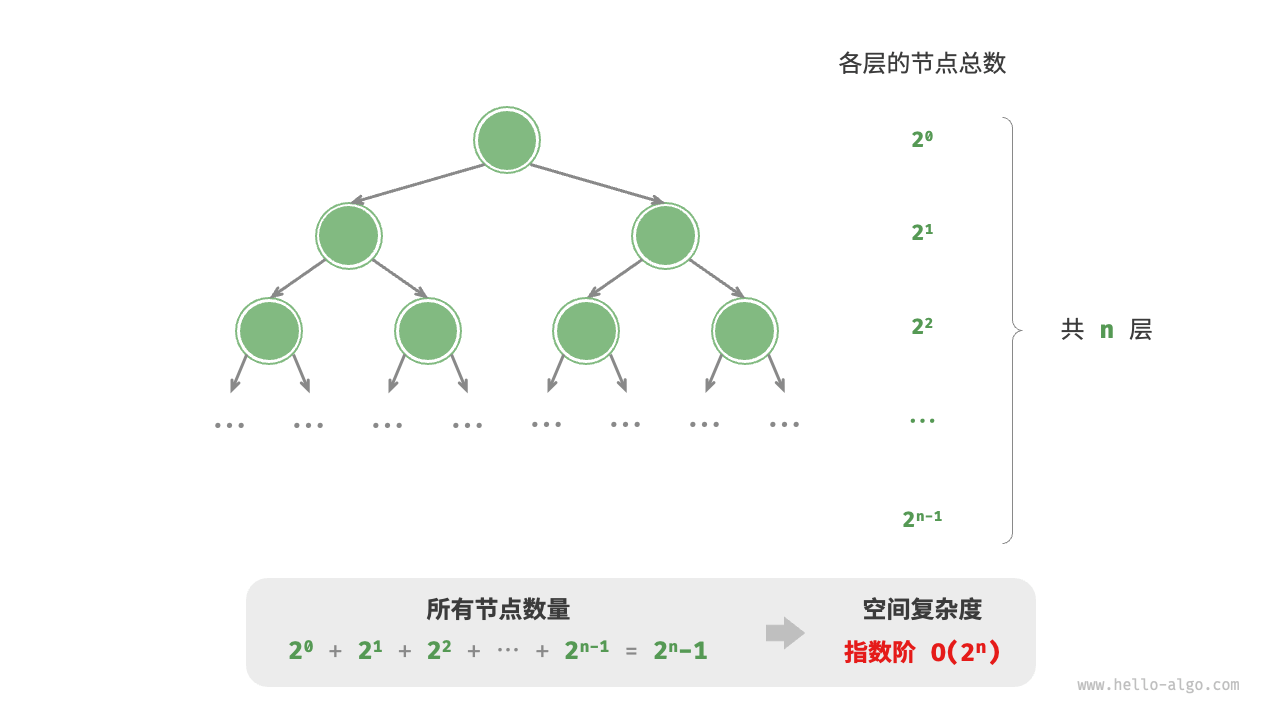
-
对数阶空间复杂度
对数阶空间复杂度((O(\log n)))在算法中并不如其他复杂度(如常数、线性、平方等)常见,因为对数阶通常与递归深度相关联。以下是一些可能具有对数阶空间复杂度的常见算法和场景:
-
递归算法:
- 二分查找:在递归实现中,二分查找的空间复杂度是 (O(\log n)),因为递归调用栈的深度是对数级别的。
- 快速排序:在最优情况下(即每次分区都能将数组均匀分割),快速排序的递归深度是 (O(\log n)),因此空间复杂度也是 (O(\log n))。
- 归并排序:尽管归并排序的时间复杂度是 (O(n \log n)),其递归实现的空间复杂度可以是 (O(\log n))(不包括用于存储结果的额外数组)。
快速排序(Quick Sort)
快速排序是一种分而治之的排序算法。它的基本思想是选择一个基准元素(pivot),然后将数组分成两个子数组,一个包含所有小于基准元素的元素,另一个包含所有大于基准元素的元素,然后递归地对这两个子数组进行排序。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15def quick_sort(arr):
if len(arr) <= 1:
return arr
else:
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quick_sort(left) + middle + quick_sort(right)
# 示例使用
arr = [3, 6, 8, 10, 1, 2, 1]
print("Original array:", arr)
sorted_arr = quick_sort(arr)
print("Sorted array:", sorted_arr)归并排序(Merge Sort)
归并排序也是一种分而治之的排序算法。它的基本思想是将数组分成两个子数组,对这两个子数组分别进行排序,然后将排序后的子数组合并成一个有序的数组。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28def merge_sort(arr):
if len(arr) <= 1:
return arr
def merge(left, right):
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] < right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result.extend(left[i:])
result.extend(right[j:])
return result
mid = len(arr) // 2
left = merge_sort(arr[:mid])
right = merge_sort(arr[mid:])
return merge(left, right)
# 示例使用
arr = [3, 6, 8, 10, 1, 2, 1]
print("Original array:", arr)
sorted_arr = merge_sort(arr)
print("Sorted array:", sorted_arr)说明
-
快速排序:
- 选择一个基准元素(pivot)。
- 将数组分成三个部分:小于基准的部分、等于基准的部分和大于基准的部分。
- 递归地对小于基准和大于基准的部分进行排序。
- 合并结果。
-
归并排序:
- 将数组分成两半。
- 递归地对每一半进行排序。
- 合并两个排序后的子数组。
这两种排序算法都是经典的分而治之算法,具有较好的性能和广泛的应用。
-
平衡树的数据结构:
- 平衡二叉搜索树(如 AVL 树、红黑树):这些数据结构在执行插入、删除和查找操作时的递归深度通常是 (O(\log n)),因此在某些实现中,可能会有 (O(\log n)) 的空间复杂度,主要用于递归调用栈。
-
迭代算法:
- 某些迭代算法在实现中可能会使用一个栈来模拟递归,从而使得其空间复杂度为 (O(\log n))。例如,某些树遍历算法在深度优先搜索时可能使用栈来存储路径信息。
需要注意的是,空间复杂度为 (O(\log n)) 的算法通常涉及递归调用或需要存储某些对数数量的信息。这种复杂度通常与算法的递归深度或树结构的高度相关。
循环与递归在空间复杂度上的差异
1 | |
函数 loop() 和 recur() 的时间复杂度都为 O(n) ,但空间复杂度不同。
- 函数
loop()在循环中调用了 n 次function(),每轮中的function()都返回并释放了栈帧空间,因此空间复杂度仍为 O(1) 。 - 递归函数
recur()在运行过程中会同时存在 n 个未返回的recur(),从而占用 O(n) 的栈帧空间。