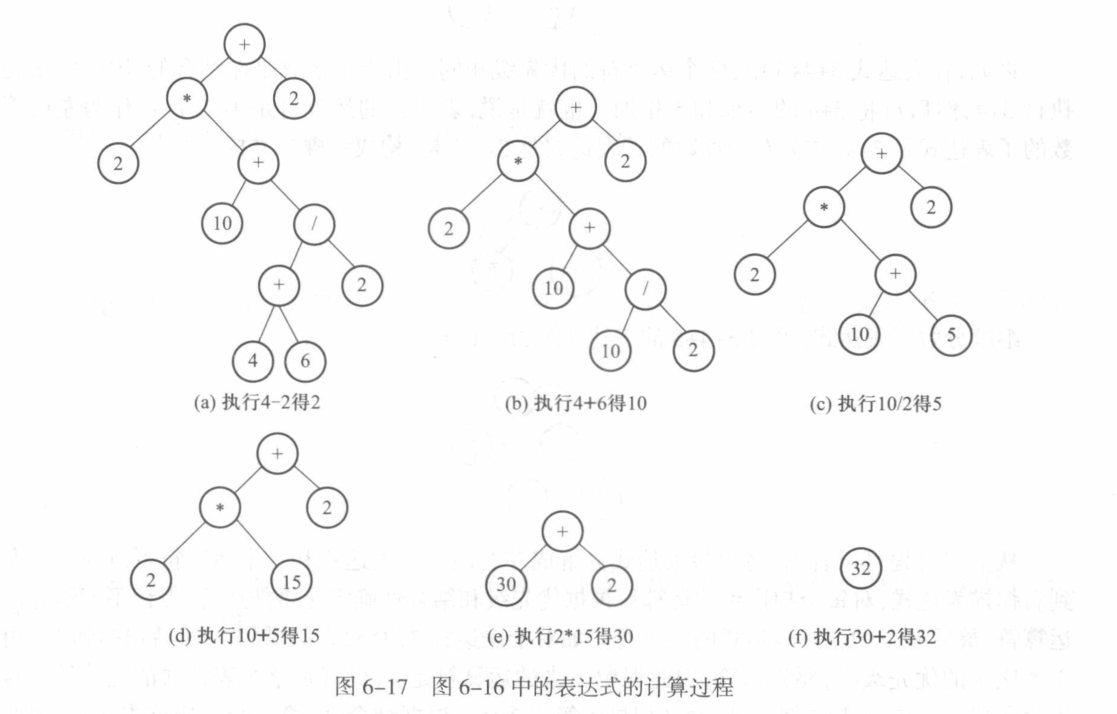
Level order traversal follows breadth-first search to visit/modify every node of the tree. As BFS suggests, the breadth of the tree takes priority first and then moves to depth. In simple words, we will visit all the nodes present at the same level one-by-one from left to right, and then it moves to the next level to visit all the nodes of that level.[1]
Preorder Traversal : root -> left sub_tree -> right sub_tree
Inorder Traversal : left sub_tree -> root -> right sub_tree
Postorder Traversal : left sub_tree -> right sub_tree -> root
分类的关键就是在于根节点在何时被遍历。
Preorder Traversal
我们首先仿照树的定义,引出前序遍历,或者叫先根遍历(Preorder Traversal)的定义:
1 2 3 4 5 6 7 8 9
//Pseudocode for Preorder Traversal if(isEmpty()){ //End for recursion: The sub_tree remaining is empty no operations here }else{ traverse the root node Preorder_traverse(left_subtree) Preorder_traverse(right_subtree) }
The atomic operations in a recursive function are the same as inorder traversal but in a different order. Here, we visit the current node first and then go to the left subtree. After covering every node of the left subtree, we will move toward the right subtree and visit in a similar fashion.
Inorder Traversal
中序遍历(中根遍历):根节点夹在左右子树之间被遍历。
1 2 3 4 5 6 7 8 9
//Pseudocode for Inorder Traversal if(isEmpty()){ //End for recursion: The sub_tree remaining is empty no operations here }else{ Inorder_traverse(left_subtree) traverse the root node Inorder_traverse(right_subtree) }
//Pseudocode for Postorder Traversal if(isEmpty()){ //End for recursion: The sub_tree remaining is empty no operations here }else{ Postorder_traverse(left_subtree) Postorder_traverse(right_subtree) traverse the root node }
/* The recursive implementation: traverse(x.left) traverse(x.right) traverse(x)
the default function if(node.left == nullptr && node.right == nullptr){ traverse the node of x }
*/
classNode; structInfo { // Add whatever you want here int current_size; // now the traversa has gone to which section int pc; //pc = 1: The initial statement //pc = 2: Has been traversed the left node //pc = 3: has been traversed the right node const Node* root_node; int *arr; int total_treesize;
Info(int current= 0, int pc= 1, const Node* root= nullptr, int *arr =nullptr, int total_treesize = 0) :current_size(current), pc(pc),root_node(root), arr(arr),total_treesize(total_treesize) { // TODO: }
~Info() { // TODO: } };
classNode { // DO NOT edit this part private: int _data; Node *_lson, *_rson; mutable Info _info; // custom data
friend Node *genTree();
public: Node();
Node(int data);
~Node();
intdata()const; const Node *constlson()const; const Node *constrson()const; Info &info()const; };
voidtraversePostOrder(const Node *const root, int *arr, int tree_size){ int currentsize = 0; Info* st = new Info[tree_size];//the simulation of stack int top = 0; st[top] = Info(0, 1, root, arr, tree_size);
structnode //define the binary tree { Type type; int data; node *lchild, *rchild; node (Type t, int d = 0, node *lc = nullptr, node *rc = nullptr){ type = t; data = d; lchild = lc; rchild = rc; } };
private: node* root;
//several tool function node* create(constchar*& s){ node *p = nullptr; node *root = nullptr; Type returntype; int value;
//creating the new tree while(*s){ returntype = gettoken(s, value); switch (returntype) { case DATA: case OPAREN: if (returntype == DATA) { p = newnode(DATA, value); } else { p = create(s); //if is a OPAREN, then we need to create a new subtree recursively! }
if (root != nullptr) { if(root -> rchild == nullptr){ root -> rchild = p; }else{ //it must be * or / root -> rchild -> rchild = p; } } break; case CPAREN: case EOL: // the creation ends return root; case ADD: case SUB: if (root == nullptr){ root = newnode(returntype, 0, p); //attention, in this case, the data 0 is meaningless for non-data operators; } else { root = newnode(returntype, 0, root); } break; case MULTI: case DIV: if(root == nullptr){ root = newnode(returntype, 0, p); } elseif (root -> type == MULTI || root -> type == DIV) { root = newnode(returntype, 0, root); } else { root -> rchild = newnode(returntype, 0, root -> rchild); } } }
//return the root node of the tree return root; }
Type gettoken(constchar *&s, int &data) { char type;
while (*s == ' ') ++s; // Skip spaces in the infix expression
if (*s >= '0' && *s <= '9') { // Encountered a number data = 0; while (*s >= '0' && *s <= '9') { data = data * 10 + *s - '0'; ++s; } return DATA; }
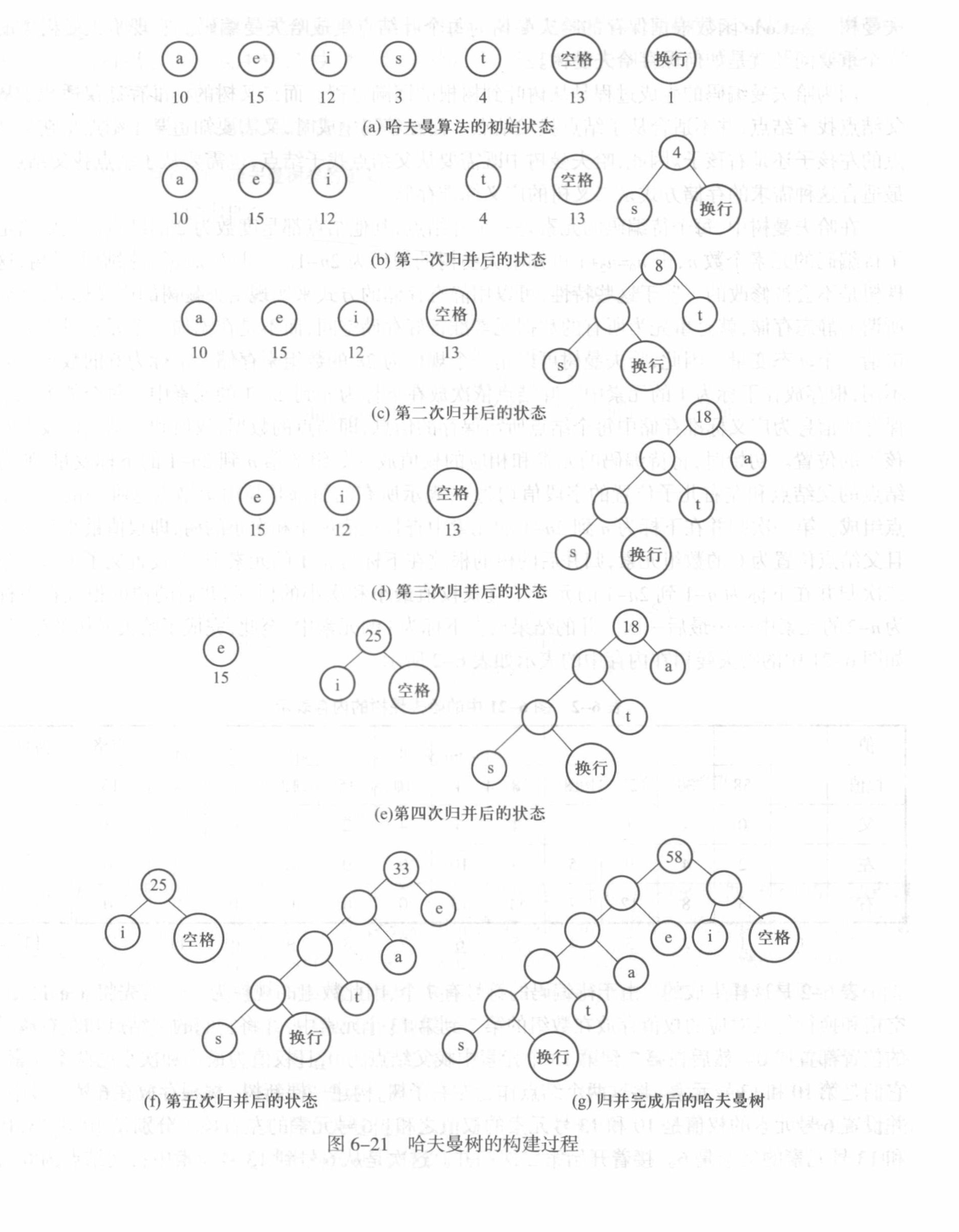
template <classT> classhfTree { private: structNode { T data; int weight; int parent, left, right; };
Node* elem; int length; // Fixed size of the tree
public: structhfcode { T data; std::string code; };
hfTree(const T* x, constint* w, int size) { constint MAXINT = 32767; int min_1, min_2; // The lowest and second lowest weights int least, second_least;
// Visualize the tree structure voidviewTree(){ std::cout << "Huffman Tree Structure:\n"; viewTreeHelper(1, 0); // Start from root (index 1) with depth 0 }
private: // Recursive helper function to print the tree voidviewTreeHelper(int index, int depth){ if (index >= length || elem[index].weight == 0) return;
// Print indentation based on depth std::cout << std::setw(depth * 4) << "";