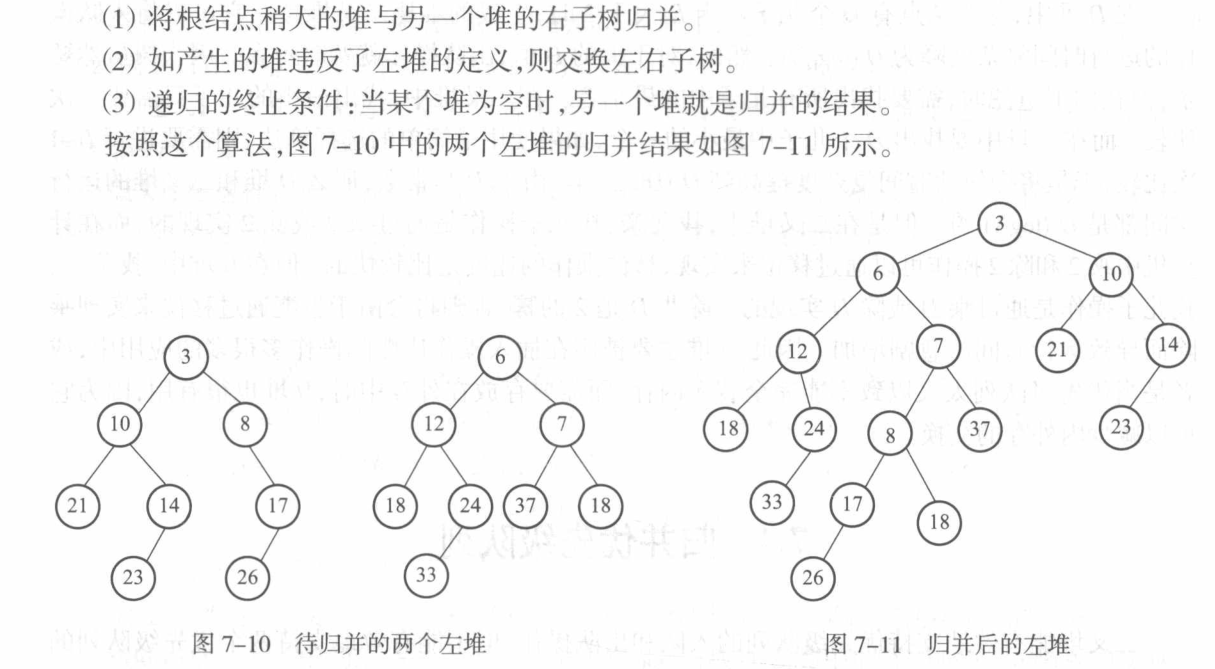
Queue is a Linear List, but if I want to place different priorities into different elements, we need to use Priority Queue implemented by Tree!
For dynamic array, insert is max but delete_max() is too slow (O(n))! However, in Sorted Dynamic Array, it is just the opposite. It’s a tradeoff for inserting and deleting if you stick to the sequential data structure. However, we can use Set AVL for getting both operations O(logn) time complexity!
In place means when sorting, the data structure doesn’t need extra space (or O(1) time complexity) to finish sorting. AVL set is very complex, where we need extra space to do several rotations in order to get the sorting.
Priority Queue Sort
Time complexity O(nlogn).
insert x for x in array (A) (build(A))
using delete_max until the priority queue is empty.
Then we get sorted for using the Priority Queue Sort.
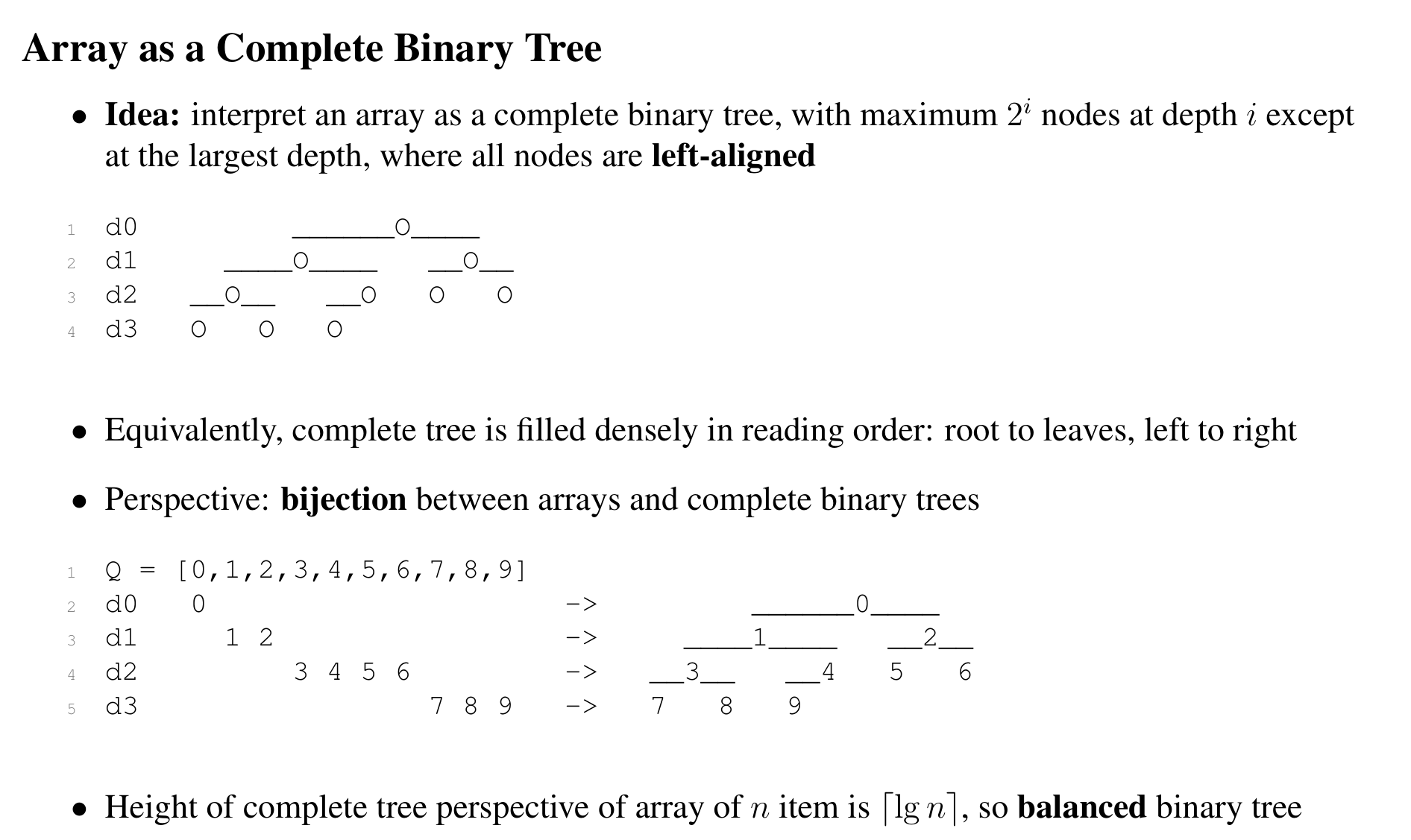
Arrays as a Complete Binary Tree
Consider the complete binary tree, there is a bijection (one to one correspondence) between this binary tree and an array traversed by a sequential order.
/* * @Author: Xiyuan Yang xiyuan_yang@outlook.com * @Date: 2025-03-27 17:25:03 * @LastEditors: Xiyuan Yang xiyuan_yang@outlook.com * @LastEditTime: 2025-03-27 17:39:34 * @FilePath: /Data_structure/single_files/Class_implementation/LeftistHeap.cpp * @Description: * Do you code and make progress today? * Copyright (c) 2025 by Xiyuan Yang, All Rights Reserved. */ #include<iostream>
structLeftistNode { int key; int npl; // Null Path Length LeftistNode* left; LeftistNode* right;
/* * @Author: Xiyuan Yang xiyuan_yang@outlook.com * @Date: 2025-03-27 19:10:30 * @LastEditors: Xiyuan Yang xiyuan_yang@outlook.com * @LastEditTime: 2025-03-27 19:13:34 * @FilePath: /Data_structure/single_files/Class_implementation/skewHeap.cpp * @Description: * Do you code and make progress today? * Copyright (c) 2025 by Xiyuan Yang, All Rights Reserved. */
#include<iostream> structSkewNode { int key; SkewNode* left; SkewNode* right;
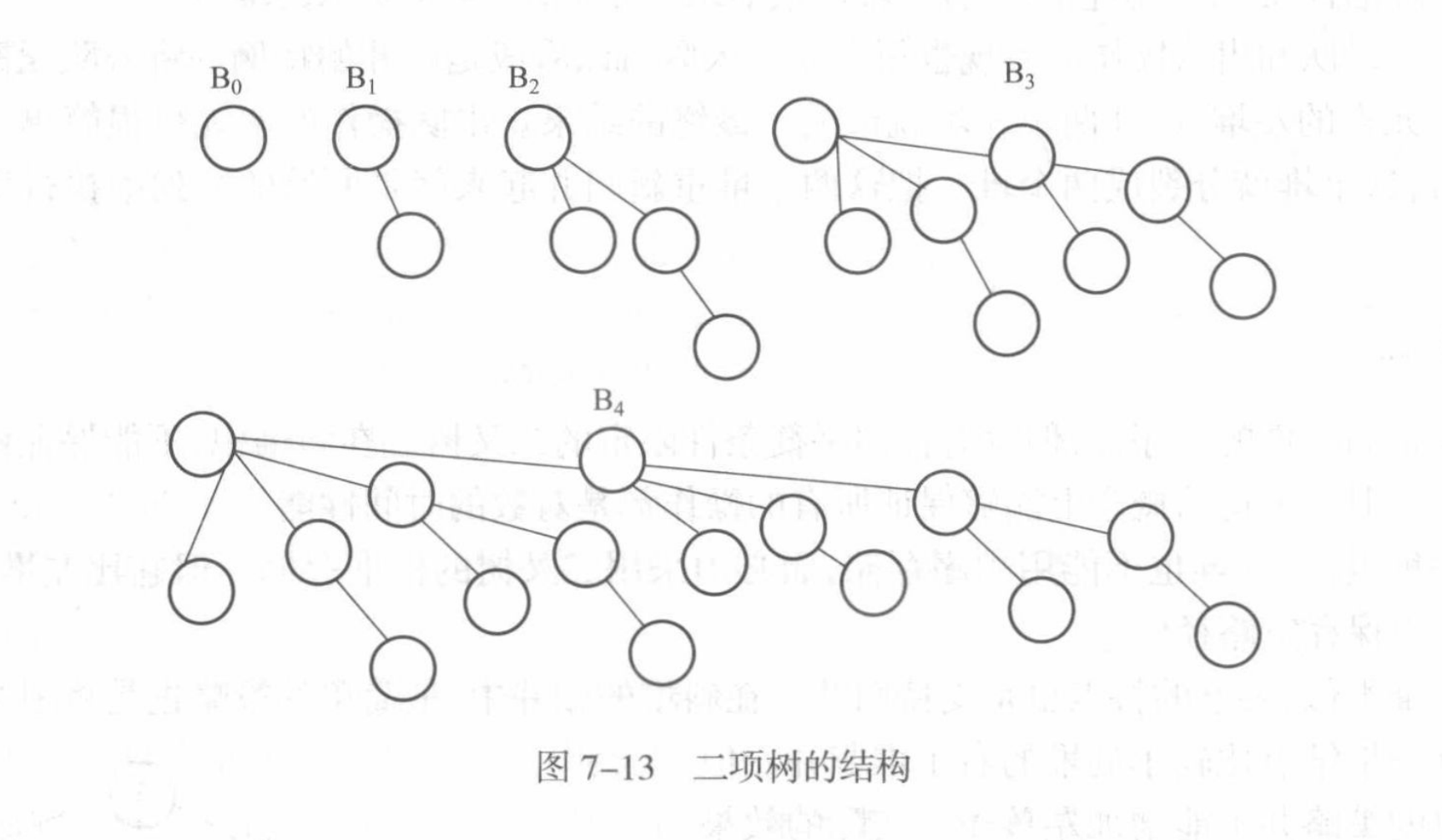
structBinomialNode { // Node structure for storing the tree, using linked storage int key; // Key value of the node int degree; // Degree of the binomial tree (number of children) BinomialNode* parent; // Pointer to the parent node BinomialNode* child; // Pointer to the first child node BinomialNode* sibling; // Pointer to the next sibling node
// Insert a new key into the heap voidinsert(int key){ BinomialNode* newNode = newBinomialNode(key); // Create a new node with the given key BinomialHeap tempHeap; // Create a temporary heap tempHeap.head = newNode; // Set the new node as the head of the temporary heap merge(tempHeap); // Merge the temporary heap with the current heap }
// Delete the minimum key from the heap voiddeleteMin(){ if (!head) return; // If the heap is empty, do nothing
BinomialNode* minNode = head; // Initialize minNode with the head of the heap BinomialNode* prev = nullptr; // Pointer to the previous node of minNode BinomialNode* curr = head; // Pointer to traverse the heap
// Find the minimum node in the root list while (curr) { if (curr->key < minNode->key) { minNode = curr; prev = curr; } curr = curr->sibling; }
// Remove the minimum node from the root list if (prev) { prev->sibling = minNode->sibling; // Bypass the minNode } else { head = minNode->sibling; // Update the head if minNode is the first node }
// Reverse the child list of minNode to create a new heap BinomialHeap tempHeap; tempHeap.head = reverseChildren(minNode->child);
// Merge the new heap with the original heap merge(tempHeap);
delete minNode; // Free the memory of the deleted node }
// Get the minimum key in the heap intgetMin()const{ if (!head) { throw std::runtime_error("Heap is empty!"); // Throw an exception if the heap is empty } int minVal = head->key; // Initialize minVal with the key of the head node for (BinomialNode* curr = head; curr; curr = curr->sibling) { minVal = min(minVal, curr->key); // Traverse the root list to find the minimum key } return minVal; }
private: BinomialNode* head; // Pointer to the head of the root list
// Reverse the child list of a node BinomialNode* reverseChildren(BinomialNode* node){ BinomialNode* prev = nullptr; // Pointer to the previous node BinomialNode* curr = node; // Pointer to traverse the child list while (curr) { BinomialNode* next = curr->sibling; // Store the next sibling curr->sibling = prev; // Reverse the sibling pointer curr->parent = nullptr; // Clear the parent pointer prev = curr; // Move prev to the current node curr = next; // Move curr to the next node } return prev; // Return the new head of the reversed list }
// Merge two binomial heaps voidmerge(BinomialHeap& other){ BinomialNode* newHead = nullptr; // New head of the merged heap BinomialNode** tail = &newHead; // Pointer to the tail of the merged heap BinomialNode* h1 = head; // Pointer to traverse the first heap BinomialNode* h2 = other.head; // Pointer to traverse the second heap
// Merge the root lists of the two heaps while (h1 && h2) { if (h1->degree < h2->degree) { // Compare degrees and add the smaller one to the merged list *tail = h1; h1 = h1->sibling; } else { *tail = h2; h2 = h2->sibling; } tail = &((*tail)->sibling); // Move the tail pointer forward }
// Append the remaining nodes from either heap *tail = h1 ? h1 : h2; head = newHead; // Update the head of the merged heap
consolidate(); // Consolidate the merged heap to ensure unique degrees }
// Consolidate the heap to ensure each degree appears only once voidconsolidate(){ vector<BinomialNode*> degreeTable(32, nullptr); // Table to store nodes by degree (max degree assumed to be 32)
BinomialNode* curr = head; // Pointer to traverse the heap BinomialNode* next;
while (curr) { next = curr->sibling; // Store the next sibling while (degreeTable[curr->degree]) { // Check if there is another node with the same degree BinomialNode* other = degreeTable[curr->degree]; // Get the other node if (curr->key > other->key) swap(curr, other); // Ensure curr has the smaller key link(other, curr); // Link the two nodes degreeTable[curr->degree - 1] = nullptr; // Clear the previous degree entry } degreeTable[curr->degree] = curr; // Store the current node in the table curr = next; // Move to the next node }
head = nullptr; // Reset the head of the heap for (auto node : degreeTable) { // Rebuild the root list from the degree table if (node) { node->sibling = head; // Add the node to the front of the root list head = node; } } }
// Link two binomial trees together voidlink(BinomialNode* child, BinomialNode* parent){ child->parent = parent; // Set the parent of the child node child->sibling = parent->child; // Add the child to the front of the parent's child list parent->child = child; // Update the parent's child pointer parent->degree++; // Increment the degree of the parent } };
// Test the BinomialHeap class intmain(){ try { BinomialHeap bh;
// Insert elements into the heap bh.insert(10); bh.insert(5); bh.insert(7); bh.insert(3); bh.insert(8);
// Print the minimum element cout << "Minimum element: " << bh.getMin() << endl;
// Delete the minimum element and print the new minimum bh.deleteMin(); cout << "Minimum element after deletion: " << bh.getMin() << endl;
// Delete the minimum element again and print the new minimum bh.deleteMin(); cout << "Minimum element after second deletion: " << bh.getMin() << endl;
std::priority_queue 是 C++ 标准模板库(STL)中的一个容器适配器,用于实现优先队列。优先队列是一种特殊的队列,其中每个元素都有一个优先级,优先级高的元素会被优先处理。默认情况下,std::priority_queue 是一个最大堆,即优先级最高的元素(即最大值)位于队列的顶部。
voidconsolidate(){ int maxDegree = static_cast<int>(std::log2(nodeCount)) + 1; std::vector<Node*> degreeTable(maxDegree, nullptr);
std::vector<Node*> roots; Node* current = minNode; if (current) { do { roots.push_back(current); current = current->right; } while (current != minNode); }
for (Node* x : roots) { int d = x->degree; while (degreeTable[d] != nullptr) { Node* y = degreeTable[d]; if (x->key > y->key) { std::swap(x, y); } link(y, x); degreeTable[d] = nullptr; d++; } degreeTable[d] = x; }
minNode = nullptr; for (Node* root : degreeTable) { if (root) { if (!minNode || root->key < minNode->key) { minNode = root; } } } }
voidlink(Node* y, Node* x){ // Remove y from the root list y->left->right = y->right; y->right->left = y->left;
// Make y a child of x y->parent = x; if (!x->child) { x->child = y; y->left = y; y->right = y; } else { y->left = x->child; y->right = x->child->right; x->child->right->left = y; x->child->right = y; } x->degree++; y->marked = false; }