voidadd(int x, int y, int v){ for (int i = x; i <= n; i += lowbit(i)) { for (int j = y; j <= m; j += lowbit(j)) { c[i][j] += v; } } }
对于子矩阵的查询,先给出查询左上角起点为$(1,1)$的矩阵的和的公式:
1 2 3 4 5 6 7 8 9 10 11
//ask for the submatrix (1,1) -> (x,y) longlongask(int x, int y){ longlong ans = 0; for(int i = x; i > 0; i -= lowbit(i)){ for(int j = y; j > 0; j -= lowbit(j)){ ans += C[i][j]; } }
/** * @brief only for two operations: modify a single point and sum a submatrix * */ structfenwick_2d_1{ int m,n;//size longlong C[MAXM][MAXN];//fenwick tree
fenwick_2d_1(int m_, int n_){ m = m_; n = n_; memset(C, 0, sizeof(C)); }
/** * @brief Modify a single element * * @param x x-index (1-based) * @param y y-index (1-based) * @param val plus val */ voidadd(int x, int y, longlong val){ for(int i = x; i <= m; i += lowbit(i)){ for(int j = y; j < n; j += lowbit(j)){ C[i][j] += val; } } }
//ask for the submatrix (1,1) -> (x,y) longlongask(int x, int y){ longlong ans = 0; for(int i = x; i > 0; i -= lowbit(i)){ for(int j = y; j > 0; j -= lowbit(j)){ ans += C[i][j]; } }
return ans; }
//(p,q) -> (x,y) longlongask_sub(int p, int q, int x, int y){ returnask(x, y)-ask(p - 1, y)-ask(q - 1, y)+ask(p, q); } };
structfenwick_2d_2 { int m, n; longlong C[MAXM][MAXN];//此处维护差分数组 voidinit(int m_, int n_){ m = m_; n = n_; memset(C, 0, sizeof(C)); }
/** * @brief submatrix(1,1) -> (x,y) all add val * * @param x * @param y * @param val * 这里的代码和上一个代码的add完全相同,但是意义不一样,因为这里的C维护的是差分数组 */ voidadd(int x, int y, longlong val){ for(int i = x; i <= m; i += lowbit(i)){ for(int j = y; j <= n; j += lowbit(y)){ C[i][j] += val; } } }
/** * @brief return the value of index (x,y) * * @param x * @param y * @return long long */ longlongask(int x,int y) { longlong ret=0; for(int i = x; i > 0; i -= lowbit(i)){ for(int j = y;j > 0;j -= lowbit(j)){ ret += C[i][j]; } }
//区间修改 /** * @brief Add val for single element (x,y) * * @param x * @param y * @param val */ voidadd(int x, int y, longlong val){ for(int i = x;i <= m;i += lowbit(i)) { for(int j = y;j <= n;j += lowbit(j)) { C1[i][j] += val; C2[i][j] += val * x; C3[i][j] += val * y; C4[i][j] += val * x * y; } } }
/** * @brief Add val for all elements in the submatrix * * @param x * @param y * @param val */ voidadd_submatrix(int x1, int y1, int x2, int y2, longlong val){ add(x1,y1,val); add(x1,y2+1,-val); add(x2+1,y1,-val); add(x2+1,y2+1,val); }
//区间查询 /** * @brief the sum of the submatrix (1,1) -> (x,y) * * @param x * @param y * @return long long */ longlongrangeAsk1(int x, int y){ longlong ans = 0; for(int i = x; i > 0; i -= lowbit(i)){ for(int j = 0; j > 0; j -= lowbit(j)){ ans += (x + 1)*(y + 1)*C1[i][j]; ans -= (y + 1)*C2[i][j] + (x + 1)*C3[i][j]; ans += C4[i][j]; } } return ans; }
longlongrangeAsk2(int x1, int y1, int x2, int y2){ returnrangeAsk1(x2,y2) - rangeAsk1(x1-1,y2) - rangeAsk1(x2,y1-1) + rangeAsk1(x1-1,y1-1); }
//单点查询 longlongask(int x,int y) { returnrangeAsk2(x, y, x, y); }
//单点修改的退化情况 voidmodifySingle(int x, int y, longlong val){ add_submatrix(x, y, x, y, val); } };
// 查询 [L, R] 区间的最小值 intquery(int L, int R){ int len = R - L + 1; // 查询区间的长度 int k = log2(len); // 找到最大的 k 满足 2^k <= len returnmin(st[L][k], st[R - (1 << k) + 1][k]); }
intmain(){ // 输入数组长度和元素 cin >> n; for (int i = 0; i < n; ++i) { cin >> arr[i]; }
// 预处理 ST 表 preprocess();
// 查询操作 int q; // 查询次数 cin >> q; while (q--) { int L, R; cin >> L >> R; // 查询区间 [L, R] cout << query(L, R) << endl; // 输出区间最小值 }
return0; }
ST表例题
A 是某公司的 CEO,每个月都会有员工把公司的盈利数据送给 A,A 是个与众不同的怪人,A 不注重盈利还是亏本,而是喜欢研究「完美序列」:一段连续的序列满足序列中的数互不相同。
int f[MAXN]; // f[i] 表示以第 i 个位置为结尾的最长完美序列的左端点位置 int st[MAXN][LOG]; // ST表,st[i][j]表示从i开始长度为2^j的区间内的最小值 int last[2][1000005]; // last[x]表示数字x最后一次出现的位置 int arr[MAXN]; // 输入数组 int n; // 数组长度
//no restriction here intquery_max(int L, int R){ int len = R - L + 1; int k = log2(len); //cout << "k" << k << endl; returnmax(st[L][k], st[R - (1 << k) + 1][k]); }
//Binary search intbinary_search(int L, int R, int target){ int low = L, high = R; while (low <= high) { int mid = (low + high) / 2; if (f[mid] >= target) { high = mid - 1; } else { low = mid + 1; } } return low; }
intmain(){ cin >> n; int m; cin >> m;
for (int i = 0; i < n; ++i) { cin >> arr[i]; }
preprocess_f(); preprocess_st();
while (m--) { int L, R; cin >> L >> R; int p = binary_search(L, R, L); //cout << "p" << p << endl;

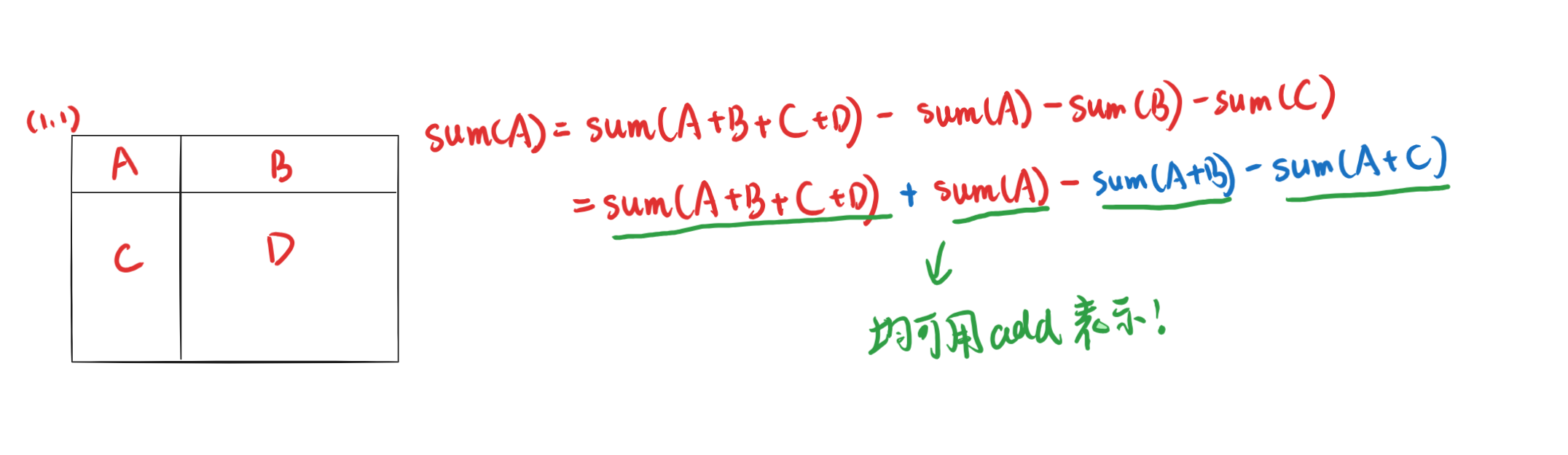
 的整数次幂位置上的值作为代表。当需要其他位置上的值时,我们通过「任意整数可以表示成若干个$k$的次幂项的和」这一性质,使用之前求出的代表值拼成所需的值。所以使用倍增算法也要求我们递推的问题的状态空间关于$k$的次幂具有可划分性。通常情况下$k$取$2$。
的整数次幂位置上的值作为代表。当需要其他位置上的值时,我们通过「任意整数可以表示成若干个$k$的次幂项的和」这一性质,使用之前求出的代表值拼成所需的值。所以使用倍增算法也要求我们递推的问题的状态空间关于$k$的次幂具有可划分性。通常情况下$k$取$2$。