CMake-Tutorial1
CMake-tutorial-episode1
Building a cpp project
在之前的C++程序中,绝大部分都是以单个Cpp文件呈现的。具体到编译器,编译器对源代码(Cpp文件)进行编译,生成中间目标文件(.obj),再由链接器将中间目标文件与一些会使用到的库文件链接在一起,最终形成一个可执行文件。
1 | |
上面两行代码是在Bash(命令行)中编译C++程序的命令行代码。
但是,随着程序体量的膨胀,我们越来越难把所有的函数放在一个cpp文件中,这样对后续代码的修改,调试等工作都增添了负担。因此,模块化开发是C++中必不可少的一个部分!
模块化开发
模块化是一种将复杂系统分解为可更好管理的模块的方式
- 模块化开发就是封装实现细节,提供模块使用接口,模块彼此之间互不影响,每个模块实现某一特定的功能
- 最大化代码重用,以最少的模块、零部件,更快速地满足个性化需求
- 原则:模块内紧耦合,模块间松耦合
在C++的模块化开发中,主要有两层含义:
- 功能模块化
- 代码模块化
对于功能模块化,程序可以拆解成若干个子功能(例如在一个学生成绩的统计表中,可以拆解为:修改、查找、排序等子功能),将每个子功能的代码实现在不同的文件中。
对于代码模块化,是指对于每一个具体的子功能,其内部有若干个自定义的函数实现,我们需要将函数的声明、函数的定义、函数的调用三者分离开来,分别放在不同的头文件或者源代码文件中。
Usage:
①全局变量或者枚举定义
这个部分往往是所有子功能都会使用到的,我们首先进行定义。
注意:谨慎使用全局变量!!!在多文件开发中,全局变量可以被任何一个文件中的任何一个函数调用并且修改!!!安全性低并且会产生很多奇怪的错误!
可以在文件中使用静态全局变量,这样可以让其他文件中的函数无法使用该变量。
因此,在这个文件中,笔者推荐只定义一些枚举变量或者变量的别名,宏定义等。
②子功能模块的实现
这个部分主要要解决两件事:函数的声明和函数的定义。函数的声明在头文件(.h)中实现,而函数的定义在源代码文件(.cpp)中实现,一般来说,我们要求在一个子模块就只有这两个文件,并且要求同名。
例如,一个子模块实现“输出”的子功能,内涵各种各样包含输出的函数,这头文件可以定义为
Output.h,源代码文件可以定义为Output.cpp。
为什么要把函数的声明和调用分离开来?
如果读者看过笔者对《C++ Primer Plus》的更新的话,会发现其书中面向对象编程的所有程序都是严格将函数定义,函数声明和函数的调用分离开来,这样做确实会更麻烦,但会有如下的好处:
提高代码组织性
函数声明(通常在头文件中)提供了函数的接口信息,包括函数名称、参数类型和返回类型。这让其他模块可以知道如何调用该函数,但不需要了解函数的实现细节。
函数定义(通常在源文件中)包含了函数的具体实现,能够避免暴露内部细节。这样其他模块只需要知道函数的声明,而不需要关心其具体实现。
加速编译过程
如果将函数声明和定义都放在同一个文件中,每次编译时都需要重新编译实现部分,而声明通常是一个接口的约定,不会发生变化。将声明和定义分离后,头文件(声明部分)可以被多个源文件共享,而源文件(定义部分)则可以独立进行编译,减少编译时间。
修改一个函数的实现时,只有源文件需要重新编译,其他依赖该函数声明的源文件不需要重新编译,提升了代码的编译效率。
代码重用
- 分离声明和定义后,可以方便地将函数声明放入一个公共的头文件,供其他项目或模块复用,而实现部分可以放在不同的源文件中。这样,开发者可以重用已有的函数实现而不需要重复编写相同的代码。
增强封装性
- 把函数声明放在头文件中,定义放在源文件中,可以隐藏函数的实现细节,提供更强的封装性。这样可以避免函数的实现细节泄漏给调用者,确保模块的内聚性和独立性。
避免重复定义
- 如果函数声明和定义混合在一个文件中,并且这个文件被多个源文件包含,那么就可能导致函数的重复定义错误。将声明和定义分离后,使用
#ifndef、#define等预处理指令来防止头文件被多次包含,从而避免这种错误。
- 如果函数声明和定义混合在一个文件中,并且这个文件被多个源文件包含,那么就可能导致函数的重复定义错误。将声明和定义分离后,使用
接口与实现分离
- 分离函数声明和定义符合“接口与实现分离”的设计原则。这样可以让调用者关注函数的功能(通过接口)而不需要关注具体的实现细节,提高模块的独立性和灵活性。如果接口发生改变,函数实现可以保持不变,反之亦然。
注意使用预编译命令,防止同一个头文件被重复定义。

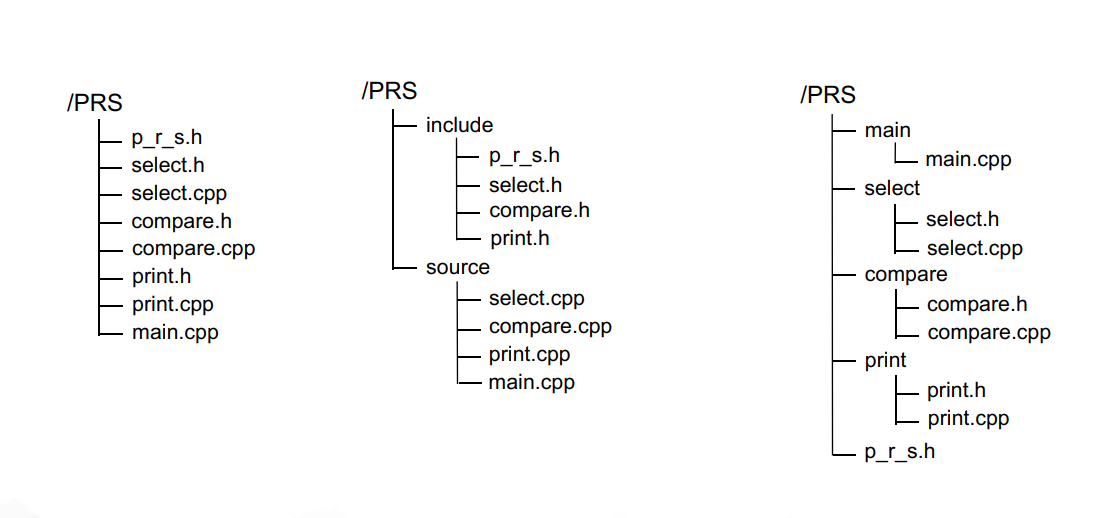
上图是三种可选的源代码放置方式。在接下来的讨论中,我们将默认选择第三种。(也是相对最复杂的一种)
What is CMake
上文我们了解了C++的模块化开发的核心思想,但是有一个问题亟需被解决:
如何让编译器编译那么多的文件并最后生成一个可执行文件?
第一种方法是手动输入各种命令行,让程序按照顺序一个一个被编译,最后main函数被编译,生成一个可执行文件。但这种方法无疑是及其繁琐的,因为每一次编译都需要程序员手动输入,大大降低了开发的效率。
一种可行的方法就是自己写一个脚本文件,让程序自动化地按顺序编译对应的头文件和源代码文件。但是还有另外一个问题,你不想每写一个新的程序就重新先写一遍脚本,同时你希望你的脚本能够在全平台运行(Linux,Windows,macOS)。
在这样的背景下,CMake诞生了。
CMake 是个一个开源的跨平台自动化建构系统,用来管理软件建置的程序,并不依赖于某特定编译器,并可支持多层目录、多个应用程序与多个函数库。
CMake 通过使用简单的配置文件 CMakeLists.txt,自动生成不同平台的构建文件(如 Makefile、Ninja 构建文件、Visual Studio 工程文件等),简化了项目的编译和构建过程。
CMake 本身不是构建工具,而是生成构建系统的工具,它生成的构建系统可以使用不同的编译器和工具链。
The Basic Usage of CMake
接下来,我们以 IDE CLion为例,介绍在CLion中如何使用CMake构建工程文件。
CLion的使用可自行查询,是一款非常好用的C++开发工具。
在打开一个新项目的时候(C++ Executable),你应该会得到如下的界面:
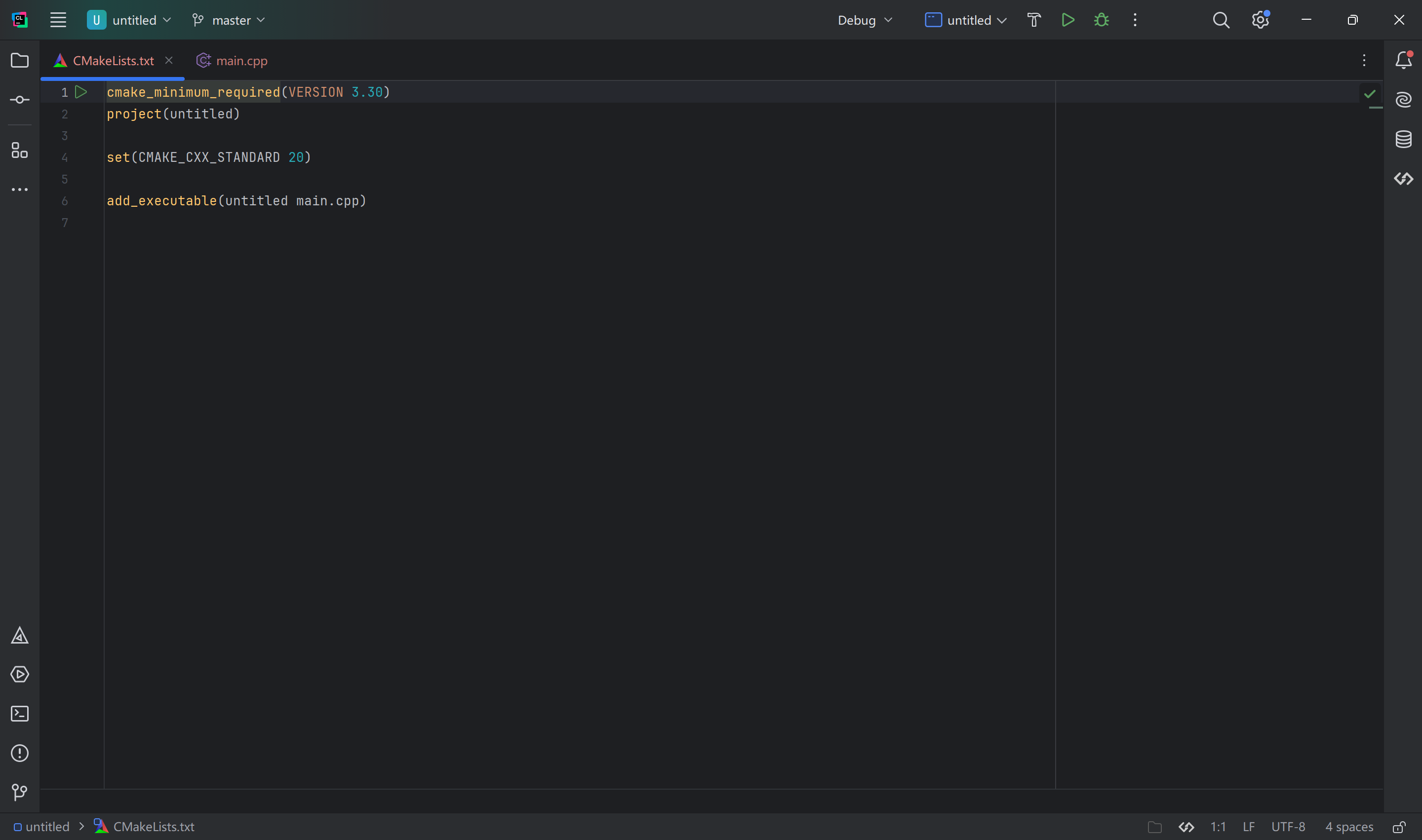
我们会发现系统自动生成了一个CMakeList.txt的文本文件,这就是上文提到的自动化编译的脚本。
1 | |
接下来我们来逐行解释这四行代码:
1 | |
规定了CMake的最低版本,这里CLion自动生成,无需修改。
如果你是直接安装了CMake,则需要自己创建一个文本文件并将内容输入,还是有一点工作量的,建议新手先使用CLion熟悉CMake的基本操作。
1 | |
这行代码定义了 CMake 项目的名称。在这个例子中,项目名是 untitled。project() 命令是用来初始化 CMake 项目,并为后续的构建设置一些基本的项目属性(如名称、版本等)
1 | |
这行代码设置了 C++ 编译标准。在这个例子中,CMAKE_CXX_STANDARD 20 表示将 C++ 标准设为 C++20。CMake 会确保编译器使用符合 C++20 标准的特性和语法来编译源代码。
1 | |
这行代码创建了一个可执行文件。add_executable() 命令告诉 CMake 将源文件(此处是 main.cpp)编译并链接成一个可执行文件。可执行文件的名称是 untitled,即编译后生成的程序文件名将是 untitled。
在点击CLion的Build后,找到文件夹的根目录,在文件夹cmake-build-debug中应该会生成一个可执行文件,说明程序已经编译完成。