Agents in Coding: A Survey
Final Assignment for MATH1116: Introduction to artificial intelligence. All rights reserved.
Source LaTeX code is here.
It hasn’t been all done yet! Collaborators welcome, feel free to contact the author: yangxiyuan@sjtu.edu.cn
AI Agents in Coding: A Survey
Author: Xiyuan Yang
Abstract
随着大语言模型(LLMs)的突破性进展,AI智能体(AI Agents)正逐步从理论概念转化为编程领域的变革性工具。本文系统性地探讨了编程智能体(AI Coding Agents)的技术演进、核心架构及其在软件工程中的应用范式。本文首先聚焦于基于Agent的三大关键技术突破:(1) 通过思维链(CoT)推理-行动协同机制;(2) 基于检索增强生成(RAG)和函数调用的环境交互能力;(3) 通过智能体的ReAct框架实现推理和外部工具调用等的统一。
接着,本文进一步分析了针对代码问题所面临的技术难点,包括执行环境的定义问题、多智能体协作问题、长上下文编码问题和多文件代码检索问题等,并以此为基础介绍了已有的技术革新,例如建立智能体环境交互界面 (Agent-Computer Interfaces) 、OpenHands社区支持多智能体框架、RoPE等优化位置编码的延长上下文方法和协议以及基于代码的检索增强生成 (Retrieval-Augmented Generation for Code)等。本文进一步总结了若干标准化评测体系(SWE-Bench, ProjectEval等)对智能体能力的量化评估方法。最后,针对智能体协议碎片化问题,本文展望了**模型上下文协议(MCP)**在工具链集成和跨平台协作中的关键作用。研究表明,编程智能体已在代码生成(79% GSM8K准确率)、错误修复(12.47% SWE-Bench解决率)等任务中展现出显著优势,标志着软件工程正迈向智能化协作的新范式。
Introduction: AI Agents
The Rise and Development of AI Agents
2024年9月,OpenAI发布了关于未来人工智能发展的五级划分体系,系统地描绘了从最初的聊天机器人 到最终实现与人类智能相当甚至超越人类的通用人工智能(Artificial General Intelligence, AGI)的演进路径。当前,随着大语言模型(Large Language Models, LLMs)的迅猛发展,AI在基础对话任务中的表现已不仅限于模拟人类交流,在诸如机器翻译、图像识别与自然语言理解等多个领域中,其能力已经接近甚至在某些方面超越了人类水平。
人工智能发展的五个阶段
| 级别 | 名称 | 描述 |
|---|---|---|
| Level 1 | 聊天机器人 (ChatBox) | 具有基本对话能力的人工智能,适用于客服、问答等场景 |
| Level 2 | 推理者 (Reasoner) | 具备逻辑推理和问题解决能力,可辅助决策分析 |
| Level 3 | 智能体 (Agents) | 能够自主执行任务或操作的 AI,如自动化流程助手 |
| Level 4 | 创新辅助者 (Innovators) | 能协助人类进行创意生成与发明设计的 AI |
| Level 5 | 组织型智能 (Organization) | 具备协调、管理复杂任务和资源分配能力的高级 AI |
与此同时,以数学推理和复杂逻辑处理为代表的认知能力也取得了显著突破。以 o3[1] 和 Deepseek [1] 等为代表的新一代推理模型在多项标准化测试与数学基准任务中展现出卓越的表现,标志着人工智能正逐步从感知层面迈向更高层次的理性思考,即将跨越第二个阶段 "推理者"的门槛。
背靠LLM解决问题能力和推理能力的快速发展,基于LLM构建的智能体 (AI Agents)正在快速崛起,当前的人工智能正处于从第二阶段(推理者)迈向第三阶段(智能体)的关键节点,2025或将成为智能体爆发的元年[2]。
智能体被广泛地定义为任何能够通过传感器感知其所处环境,并通过执行器对环境施加影响的实体 [2]。基于LLM构建的智能体因其强大的泛化能力和适应性,正在深刻重塑编程领域。AI Coding Agent 已经展现出卓越的代码生成、错误检测与自动修复能力,显著提升了开发效率与代码质量。本文将聚焦于AI智能体在编程领域的应用现状、技术挑战及未来发展趋势,探讨其对软件工程范式的深远影响。
Architecture Design of AI Agents
Reasoning Enhancement for Agents
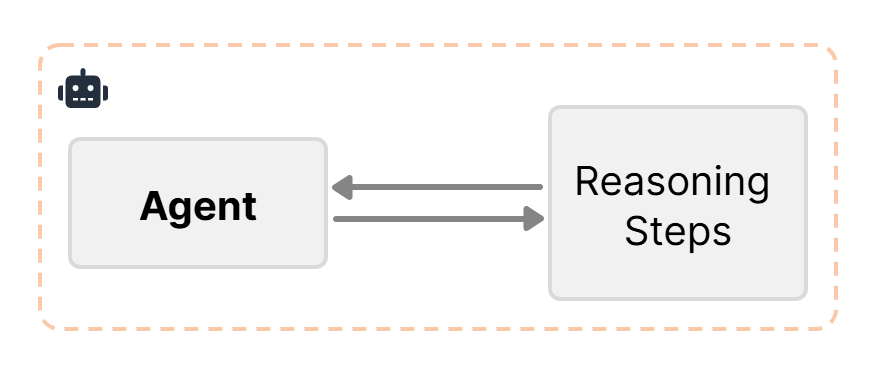
基于LLM的智能体仍然遵循Next-Token Prediction架构,即自回归(Autoregressive)生成。模型从左到右依次预测序列中的每个词元 (tokens),每一步的预测都依赖之前生成的文本,在模型输出的每一个过程中,输出的是对不同词元的概率分布,并且最终通过采样 (贪心搜索、束搜索)等方法确定最新词元的输出。
前人的研究表明让LLM在解决复杂推理问题时加入推理的步骤,可以提升其解决复杂问题的准确率。
- 思维链 (Chain of Thought)
思维链方法 (Chain of Thought) [3] 通过引导LLM显式生成中间推理步骤,显著提升了其在数学推理的性能,并且可以通过通过Few-shot示例或Zero-shot指令(如"Let’s think step by step")激活模型预训练中学到的逻辑模式。实验表明在在GSM8K数学数据集上,CoT使GPT-3的准确率从17%提升至79%。
- 思维树 (Tree of Thought)
思维树 (Tree of Thought) [4] 在思维链的基础之上,将单一路径的链式推理升级为树形结构的多路径探索,以解决CoT的局部最优局限。其关键创新点在于并行推理分支,即在每一步生成多个可能的中间步骤,通过评估函数筛选最优路径,并结合传统的树搜索算法。例如在需要多步规划的24点游戏中,ToT达到了74%的准确率,远超CoT的9%。
1 | |
External Tool Use for Agents
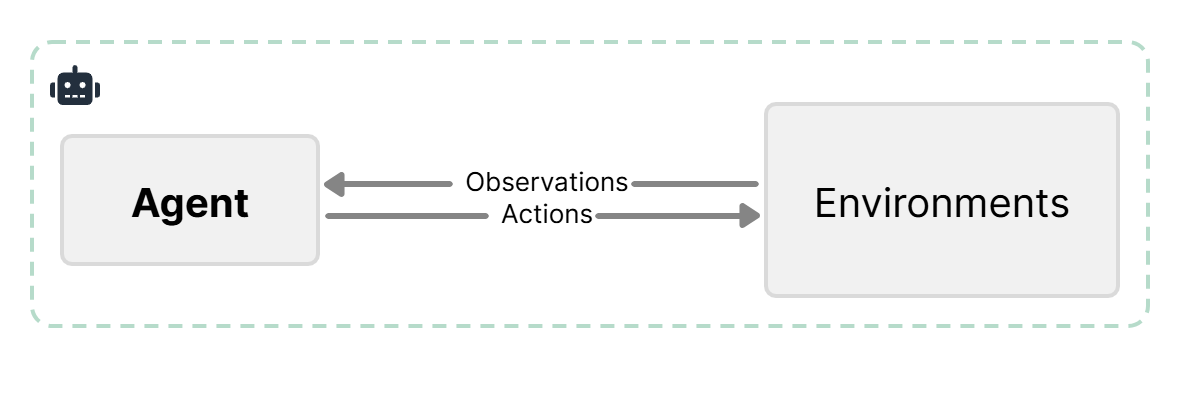
基于预训练参数的大语言模型具有滞后性,即孤立的大语言模型很难获取到网络上的最新资讯,成为了LLM应用的重要瓶颈之一。因此,"让模型联网"是解决智能体滞后性的关键。
在之前的研究中,已经有多种行之有效的方法使LLM及时获取外部信息,与环境进行交互。
- 检索增强生成 (Retrieval-Augmented Generation)
检索增强生成 (Retrieval-Augmented Generation, RAG) [5] 允许LLM在生成回答前从外部知识库中检索相关信息。RAG首先使用预训练分词模型 (如BERT [6]) 将查询文本和文档编码为固定维度的向量建立索引,在检索时,计算查询向量与文档向量的相似度,返回Top-K最相关的文档片段。最终在推理阶段引入一个检索器 (retriever),提取目标文档作为上下文传递给生成模型,从而提升答案的准确性和时效性。
- 函数调用机制 (Function Calling)
函数调用 (Function Calling) 允许LLM Agent在执行任务时调用外部API、工具或数据库接口,实现更加复杂的任务,例如网络搜索,天气查询等。
1 | |
The ReAct (Reasoning and Action) Agent Model
结合上文两种增强智能体解决现实问题能力的方法,基于智能体的ReAct框架 (Reasoning and Actions) [7],可以从内外两方面同时提升智能体在复杂环境中的自主决策能力。其核通过一个结构化的循环机制,使智能体在每一步决策中先进行"思考"(即推理),再决定"执行什么动作"(即行动)。这种"思考-行动"的交替过程,使智能体能够根据当前状态和历史经验,动态调整策略。实验结果表明,ReAct框架使智能体在HotpotQA [8] 数据集上获得了35.1%的准确率,远高于仅仅使用CoT (29.4%)或者Act架构 (25.7%)。此外,React架构支持单样本提示 (One-shot Prompting),多样本提示 (Few-shot Prompting) 和模型微调 (Fine-tuning)。
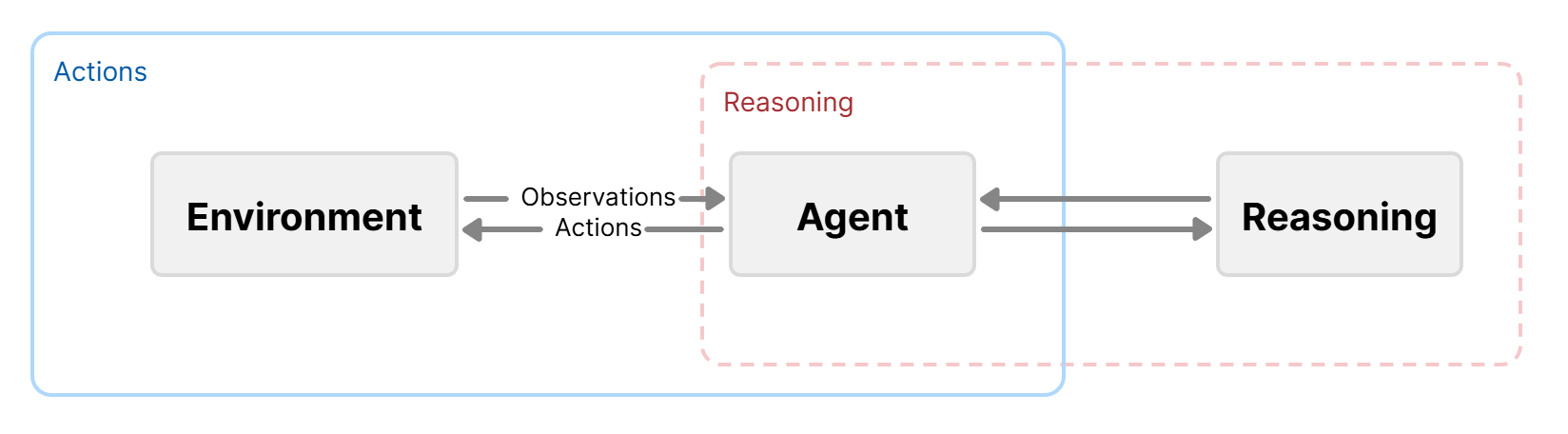
AI Coding Agents
在智能体技术迅速发展的背景下,AI Coding Agent(编程智能体)作为人工智能与软件工程深度融合的产物,正逐步成为推动软件开发范式变革的重要力量。AI Coding Agent 是指能够理解用户需求、自动编写、调试和优化代码的人工智能系统,其核心任务包括但不限于:代码生成 (Code Generation), 程序理解 (Program Understanding),错误检测 (Bug Detection and Fixing),自动化测试 (Test Case Generation) 和 代码优化 (Code Optimization)等。
OpenHands[3]社区,聚力于AI智能体在软件工程领域的应用。其提出编程智能体的基本行为模式是:智能体能够感知环境状态(例如先前的操作和观察结果),并在处理用户指定任务时生成可执行的操作,并以此为基础定义了状态和事件流(State and Event Flow), 环境观察(Observations)和智能体的抽象 (Agent Abstraction)等定义,为Coding Agents的构建提供基本框架。
Key Technical Components
Technical Difficulties
基于在 1.3 所介绍的编程智能体所需要解决的问题,可归纳出如下若干技术难点:
-
环境适配的复杂性 (Difficulty in defining environment): 智能体在面对软件开发任务时需要自动配置编码环境和测试环境,并且外部工具的嵌入和在GitHub等仓库中多种类型的文档的解析等操作为智能体定义合适的开发环境增添了阻力。对于人类来说较为轻松的环境识别工作对于AI智能体来说颇具难度。
-
复杂编程任务和错误自动化处理 (Bug detection and automated fixing):智能体在遇到复杂代码报错等问题时,需要能够自主规划行为并且修复代码错误。
-
多智能体协作任务:智能体在做开发时往往会涉及多智能体协作的任务,例如不同的智能体分别处理不同的代码并之间相互交流,模拟人类开发团队的沟通提升单智能体编码的效率。
-
多文件代码处理 (File Localization):智能体在操作GitHub等代码仓库是需要快速检索并且定位到关键代码的位置,并且了解不同文件代码的逻辑结构。
Innovations
为了解决上述难点,相关工作做出了若干技术创新,下面一一介绍之。
Agent-Computer Interfaces
在传统的开发环境中,主要包括命令行界面(Command Line Interface) 和 图形用户界面(Graphical User Interface),Agent在面对传统的两种用户交互界面适配性低,同时,Agent的开发依赖于外部工具的使用,例如Shell环境和Python解释器等,而SWEAgent [9] 通过构建智能体交互环境,实现提升智能体在编码领域的表现。
文中总结了ACI相比于传统UI的相关特点,包括:
- 简洁高效的操作指令:例如在Bash命令行下需要更加简洁的参数后缀,并且需要将操作设计整合为紧凑的最小化的操作单元。
- 环境反馈需信息浓缩:优质反馈应当精炼呈现环境状态关键信息(及代理操作产生的效果),避免冗余细节。例如文件编辑时,仅反馈变更内容的核心更新即可。
- 防护机制能遏制错误传播:与人类类似,语言模型在编辑/搜索时会产生错误且难以自主修正。内置防护措施(如自动检测语法错误的代码检查器)可加速错误识别与修复。
使用简洁高效的环境配置符合Linux哲学中小即是美 (Write programs that do one thing and do it well [4])的思想,解决了环境配置复杂性的问题。
最终的实验结果表明,以GPT-4 Turbo作为基座模型,SWE-Agent在SWE-Bench [10]上获得了**12.47%**的准确率,远高于纯RAG的Agent或者Shell-Only的Agent。
Multi-Agent Collaboration in Coding
在OpenHands框架中,社区接入了多种多智能体框架并测试其功能,例如Autogen和Camel等。下表展示了在OpenHands社区支持的若干智能体框架以及其支持的功能,例如外部工具箱 (External Tool Libraries) 和 指标集评测 (Evaluation FrameWork) 等。
Comparison of Agent Frameworks in OpenHands [11]
| Framework | Domain | GUI | Tools | Code Exec | Web | Multi-agents | Human-AI | Agent Hub | Eval | Agent QC |
|---|---|---|---|---|---|---|---|---|---|---|
| AutoGPT | General | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✓ |
| LangChain | General | ✓ | ✓ | ✗* | ✗* | ✗ | ✗ | ✓ | ✗ | ✗ |
| MetaGPT | General | ✗ | ✓ | ✗ | ✓ | ✓ | ✗ | ✓ | ✗ | ✓ |
| AutoGen | General | ✗ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ |
| AutoAgents | General | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ |
| Agents | General | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ | ✗ | ✗ | ✗ |
| Xagents | General | ✓ | ✓ | ✗ | ✓ | ✓ | ✗ | ✓ | ✗ | ✗ |
| OpenAgents | General | ✓ | ✗ | ✓ | ✓ | ✓ | ✗ | ✓ | ✗ | ✗ |
| GPTSwarm | General | ✗ | ✓ | ✗ | ✗ | ✓ | ✓ | ✗ | ✗ | ✗ |
| AutoCodeRover | SWE | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ |
| SWE-Agent | SWE | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ |
| OpenHands | General | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
*No native support. Third-party commercial options are available.
Agents Handling with Long-Context Code-filling Tasks
Transformer [12] 架构存在位置编码 (Positional Encoding)的概念,用来实现对序列文本的位置信息的建模。但是,常规Transformer架构通常仅支持512-4k tokens的上下文窗口,对于较长的代码任务,其面对超长代码文本会出现生成准确率下降,幻觉严重等问题。
旋转位置编码 (Rotary Position Embedding(RoPE)) [13] 等方法,可以通过旋转位置编码的方式,构造旋转矩阵来存储位置信息。
1 | |
1 | |
此外,基于RoPE, NTK-aware scaling [14] 等注意力算法的优化机制,针对超长文本的延伸协议 (Long-Context Extension Protocol) [15],实现了测试若干方法在不同数据集(例如RULER [16] 等)上的表现,最终得出结论:在不同的注意力机制下,**困惑度(perplexity)**作为核心性能指标发挥关键作用。
Retrieval-Augmented Generation for Code Localization
对于代码复杂的函数调用逻辑,智能体有时需要在代码块中检索特定片段,来学习用户的代码框架和逻辑。DocPrompting [17],利用Retriever - Generator架构从文档池中检索得到相关代码的教程文档,并返回给代码生成器,使其根据检索增强出的文档和用户自然语言的输入生成最终代码。实验表明,在DocPrompting帮助下的LLM帮助生成代码的效果都远高于直接生成,尤其在用户需要处理个性化任务的情况下。
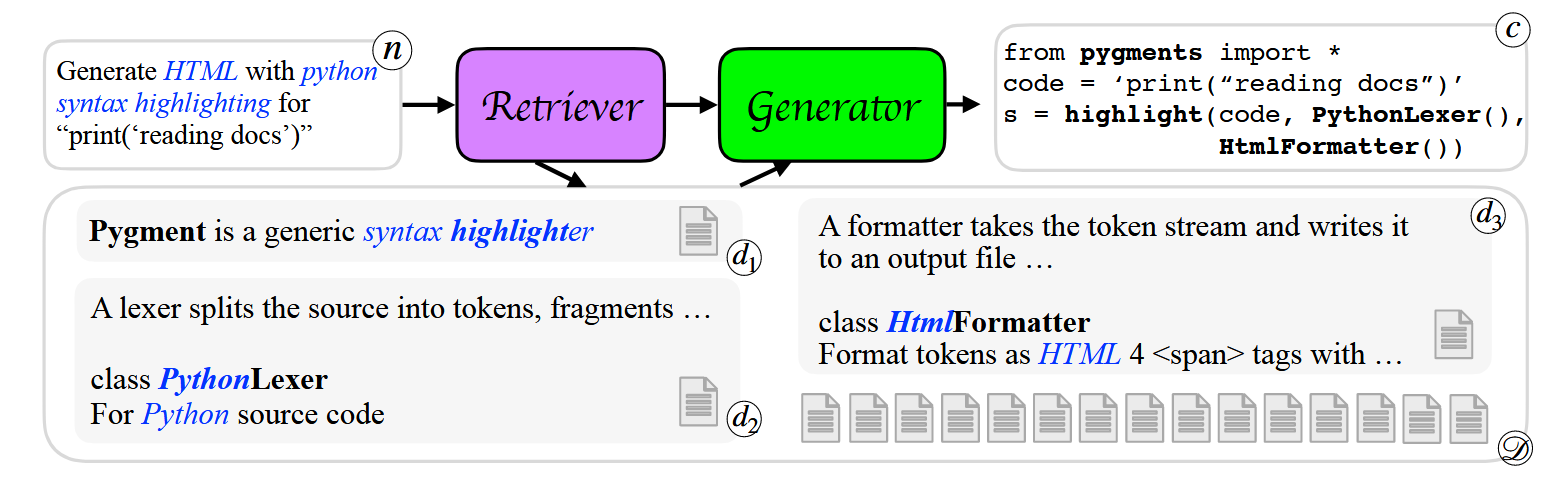
Benchmark
正如Shunyu Yao提出[5],对智能体的更加准确的评测(Evaluation)、指标集(BenchMark)和环境(Environment)在未来的重要性将要超过模型的训练和若干优化方法。下表列举出如今评测Code Agent表现的若干数据集及其具体表现。
Several Benchmark for Coding Agents
| 数据集名称 | 简介 |
|---|---|
| RedCode [18] | 评估代码智能体生成和执行危险代码安全性的基准,包含RedCode-Exec(4050个风险测试案例)和RedCode-Gen(160个提示)两部分。 |
| SWT-Bench [19] | 基于GitHub真实问题的新基准,用于评估LLM生成测试用例的能力。 |
| StackEval [20] | 包含StackEval(大规模Stack Overflow问题基准)和StackUnseen(动态新内容基准)两个数据集,评估编码辅助任务性能。 |
| TheAgentCompany [21] | 评估LLM代理在模拟真实办公环境中完成任务能力的基准。 |
| SciReplicate-Bench [22] | 评估LLM从研究论文生成代码能力的基准,提出算法理解和代码实现质量的新评价指标。 |
| ProjectEval [23] | 项目级代码生成的自动评估框架。 |
| MLE-Bench [24] | 智能体自动化解决Kaggle竞赛的测评指标 |
Future Outlook
如今,随着算力资源的蓬勃发展和各种新兴架构的提出,基于LLM的Coding Agent的表现也随着基座模型能力的提升而不断提升。与此同时,构建多智能体系统 (Multi-Agent Systems)将会是未来智能体区别于Only-LLM的发展趋势。基于对未来智能体的展望,下文将详细介绍模型上下文协议 (Model Context Protocol (MCP))在未来编程智能体发展会发挥的巨大作用。
Model Context Protocol
Model Context Protocol(MCP)是由 Anthropic 在2024年底推出的基于LLM的开放标准[6],是一种智能体调用语言模型或工具的标准化协议。其定义智能体如何与语言模型进行交互、支持多模型协同推理并且提供统一接口来调用外部工具和服务。
- 解耦模型与代码逻辑:面对不同API厂商的不同接口,传统的LLM调用需要硬编码针对不同模型的接口格式,使模型设置和代码逻辑高度耦合。MCP起到了中间层协议的作用,通过定义通用的请求/响应格式支持抽象模型调用逻辑且支持本地模型, API模型等多种服务。
1 | |
- 集成外部工具与服务:聚焦Agent对外部工具的调用,MCP同样提供了一套标准化协议,使得智能体可以使用标准化的接口调用第三方的工具API工具,例如GoogleMap, GoogleSearch等等。
1 | |
针对代码问题,MCP的出现和普及有利于主流IDE的插件生态的不断丰富 (例如Vscode extension的扩展),使Coding Agent在代码问题上可以更快速地调用第三方工具链,现如今,cline [7]等支持MCP的插件已经初具规模。
Conclusion
本文在介绍了Agent的三大基础技术突破 (CoT, RAG, ReAct Model)之后,分析了针对AI Coding Agents 解决代码问题所面临的技术难点,包括执行环境的定义问题、多智能体协作问题、长上下文编码问题和多文件代码检索问题等,并以此为基础介绍了已有的技术革新,例如建立智能体环境交互界面 (Agent-Computer Interfaces) 、OpenHands社区支持多智能体框架、RoPE等优化位置编码的延长上下文方法和协议以及基于代码的检索增强生成 (Retrieval-Augmented Generation for Code)等。结论表明MCP协议是未来多元化智能体实现统一架构的关键,且当今若干测评智能体代码能力的数据集显示编程智能体已在代码生成(79% GSM8K准确率)、错误修复(12.47% SWE-Bench解决率)等任务中展现出显著优势,已经在多个指标和数据表现上超越一般人类程序员 (例如MLE-Bench)。未来软件工程将要接受智能体的深刻变革。
References
[1] DeepseekAI. (2025). Deepseek-V3 Technical Report.
[2] Russell, S., & Norvig, P. (2016). Artificial Intelligence: A Modern Approach.
[3] Wei, J., et al. (2022). Chain of Thought Prompting Elicits Reasoning in Large Language Models.
[4] Yao, S., et al. (2023). Tree of Thoughts: Deliberate Problem Solving with Large Language Models.
[5] Gao, L., et al. (2024). Retrieval-Augmented Generation for Large Language Models: A Survey.
[6] Devlin, J., et al. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
[7] Yao, S., et al. (2023). ReAct: Synergizing Reasoning and Acting in Language Models.
[8] Yang, Z., et al. (2018). HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering.
[9] Yang, J., et al. (2024). SWE-Agent: Agent-Computer Interfaces Enable Automated Software Engineering.
[10] Jimenez, C., et al. (2024). SWE-Bench: Language Models Resolve Real-World GitHub Issues.
[11] Wang, L., et al. (2025). OpenHands: An Open Platform for AI Agent Development and Evaluation.
[12] Vaswani, A., et al. (2023). Attention Is All You Need.
[13] Su, J., et al. (2023). RoFormer: Enhanced Transformer with Rotary Position Embedding.
[14] Peng, B., et al. (2023). YARN: Efficient Context Window Extension of Large Language Models.
[15] Lu, X., et al. (2024). A Controlled Study on Long Context Understanding of Large Language Models.
[16] Hsieh, C., et al. (2024). RULER: What’s the Real Context Window of Your Language Model?
[17] Zhou, S., et al. (2023). DocPrompting: Generating Code by Retrieving the Docs.
[18] Guo, B., et al. (2024). RedCode: Risky Code Execution Detection Benchmark.
[19] Mündler, N., et al. (2025). SWT-Bench: Testing and Validating Real-World Software Engineering Tasks.
[20] Shah, P., et al. (2024). StackEval: Benchmarking LLMs on Coding Assistance Tasks.
[21] Xu, L., et al. (2024). TheAgentCompany: Benchmarking LLM Agents in Simulated Work Environments.
[22] Xiang, Y., et al. (2025). SciReplicate-Bench: Benchmarking LLMs on Agent-Driven Scientific Code Generation.
[23] Liu, J., et al. (2025). ProjectEval: A Benchmark for Programming Agents.
[24] Chan, S., et al. (2025). MLE-Bench: Evaluating Machine Learning Agents on Kaggle-Style Competitions.
Update to be done in the future (Maybe?😊)
- Add more specific description of MCP.
- Add more Key technical innovations.
- Make the passage more logical and concise.
- Try to run my own experiments!
- Explain ROPE more clearly! Try to have some my own points of view.
- https://openai.com/index/introducing-o3-and-o4-mini/ ↩
- https://finance.people.com.cn/n1/2025/0309/c1004-40434744.html ↩
- https://docs.all-hands.dev/ ↩
- https://en.wikipedia.org/wiki/Unix_philosophy ↩
- https://ysymyth.github.io/The-Second-Half/ ↩
- https://www.anthropic.com/news/model-context-protocol ↩
- https://github.com/cline/cline ↩