My-CSAPP
Memory Hierarchy and Cache Memories
Storage technologies and Trends
RAM: Random Access Array
- SRAM: 静态 RAM,速度快,但是结构设计复杂,适合 Cached Memories
- DRAM: 动态 RAM,速度慢,但是价格便宜,适合主要的内存和 frame buffers
当然可以!以下是根据你提供的幻灯片内容整理的中文表格,介绍各种非易失性存储器(Nonvolatile Memories)及其特性:
| 类型 | 全称 | 是否可写 | 擦除方式 | 特点/用途 |
|---|---|---|---|---|
| ROM | Read-Only Memory(只读存储器) | 不可编程(出厂时已固化) | — | 用于存储固件,如 BIOS、显卡/网卡控制器等 |
| PROM | Programmable ROM(可编程只读存储器) | 仅一次编程 | — | 用户可一次性写入数据,之后不可更改 |
| EPROM | Erasable PROM(可擦除可编程只读存储器) | 可多次编程 | UV 紫外线或 X 射线批量擦除 | 需专用设备擦除,常用于早期嵌入式系统 |
| EEPROM | Electrically Erasable PROM(电可擦除可编程只读存储器) | 可多次编程 | 电子信号逐字节擦除 | 支持在线修改,适合小量数据存储(如配置参数) |
| Flash Memory | 闪存(基于 EEPROM 技术) | 可多次编程 | 按块(block-level)部分擦除 | 广泛用于 U 盘、SSD、手机、平板、MP3 播放器等;寿命约 10 万次擦写 |
Bus Structure
- Bus: 数据总线,支持数据流从主存和 CPU 直接的快速传输
- e.g. 汇编指令中有 CPU 从主存中读取数据,存储到寄存器中,这就具体涉及到了数据总线的功能
在具体设计上,寄存器和 ALU 等 CPU 中的核心计算单元首先和总线接口进行交互,然后:
- 总线接口和 IO 桥之间存在系统总线进行 IO 交互
- IO 桥和主存之间存在内存总线进行存储数据交互
Disk: Geometry and Capacity
Geometry
- 磁盘,移动条
- 读取速度远低于 RAM,但是断电数据不会消失
Capacity

- 盘片(Platter):磁性材料圆盘,高速旋转(5400~15000 RPM)
- 磁头(Head):悬浮在盘片上方,负责读/写磁性信号
- 磁道(Track):盘片上 concentric circles(同心圆),数据按磁道存储
- 扇区(Sector):每个磁道被划分为多个扇区,传统为 512 字节,现代多为 4KB(Advanced Format)
- 柱面(Cylinder):所有盘片同一半径位置的磁道组成一个柱面
- 寻道臂(Actuator Arm):带动磁头移动到目标磁道
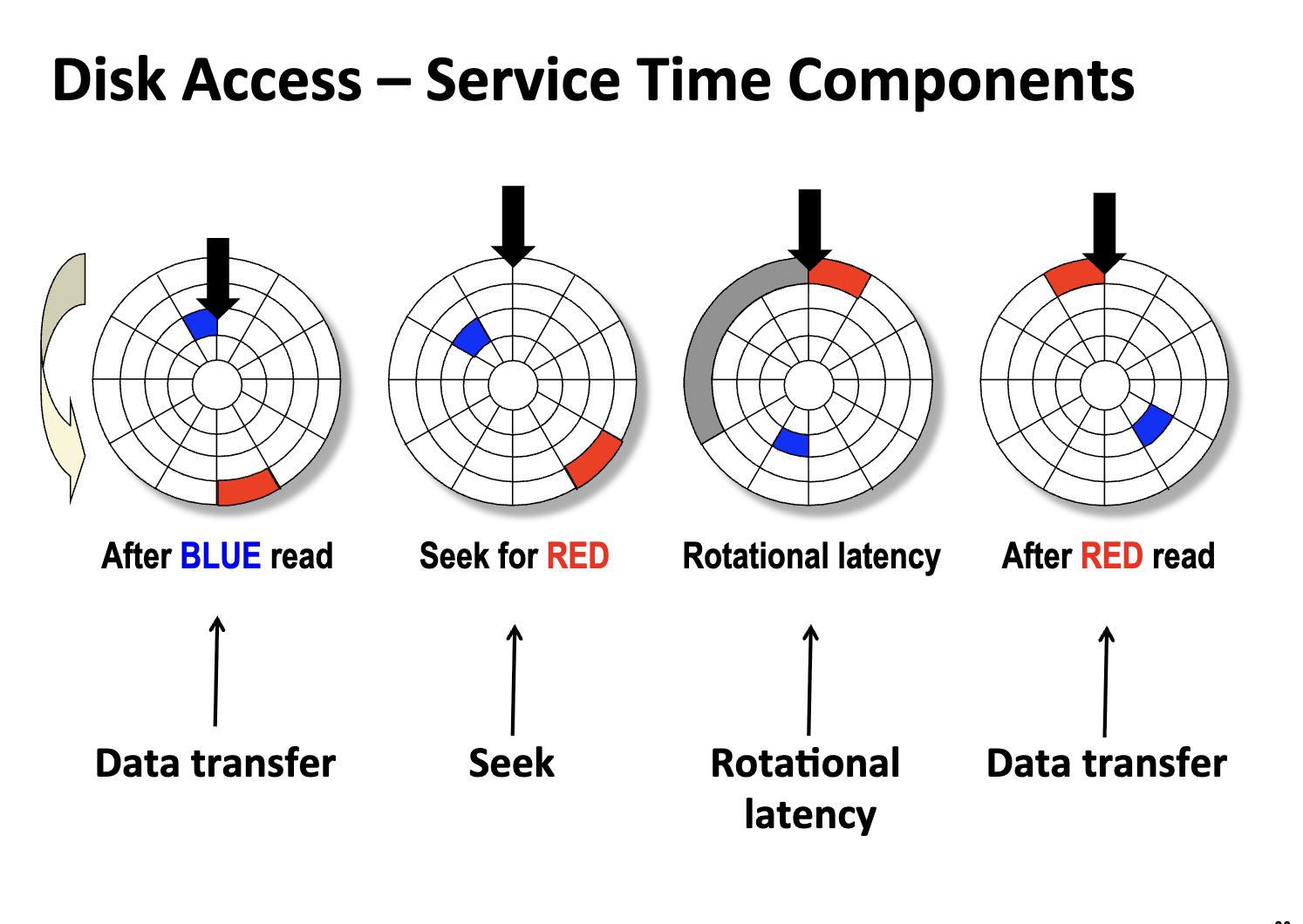
寻道臂移动磁头到目标柱面,并等待旋转(Rotational Latency),等待目标扇区转到磁头下方
Seek 和 Rotation Latency 是磁盘读写的关键时间瓶颈(毫秒级别)
Logical Disk Blocks
操作系统负责处理上层软件和底层硬件系统的交互,从上层来看,操作系统提供了一种极为便利的抽象,让上层软件无需考虑底层设计的硬件细节,通过统一的接口进行存储器的读取(内存/硬盘)
- 物理的硬盘存储器会被操作系统映射为不同编号的 logical disk blocks.
- 一个 LBA 往往代表一个 sector (4KB)
- 两者之间的映射查表由专门的部分进行处理 (FFL)
IO Bus
在上文中,system bus, memory bus 串联起来了 IO 总桥、CPU 中的 Bug interface 和主存。与此同时,IO Bus也在比较低速的外部设备(外部 IO 设备、Disk 等)和 IO 总线连接。
因为有了 IO 总桥,计算机可以实现从磁盘中读取数据,并存储到内存中。
- CPU 直接对 Disk 发出指令
- 磁盘通过 IO Bus 和 Memory Bus 直接对内存进行更新
- 数据复制读取完成后,磁盘通过 IO Bus 和 System Bus 通过 Interrupt 的机制来告知 CPU
磁盘读写非常耗时,如果 CPU 等待磁盘完成读写,会严重阻碍 CPU 的运行。
SSD
- 从接口上和 Rotating Disk 完全保持一致,但是在硬件上读取速度更快。
- Flash Translation Layer: 类似于传统的磁盘控制器
SSD 在物理上和传统的机械硬盘不同,无法实现数据的原地覆写,无法擦除原始的物理页,而是找一个新的数据块并写入新数据,然后更新映射表。现代 SSD 会通过垃圾回收,负载均衡等操作进行优化,尽可能避免 SSD 中存在大量的无效数据块。
- SSD 的数据读取,能源消耗都显著低于 Rotating Disks
- 这也导致了更加高昂的造价和更宝贵的使用寿命。
CPU-Memory Gap
计算机的整体提速是一个非常系统的工程难题:
- 不同组件相互制约,限制速度的因素可能有很多
- Scale Up 的工程美学
Locality of Reference
局部性原理: Principle of Locality: Programs tend to use data and instructions with addresses near or equal to those they have used recently
- temporal locality: 时间局部性、缓存
- spatial locality: 空间局部性
例如,对于一个数组遍历求和:
- Data References
- 数组是一段连续的内存:空间局部性
- 求和变量
sum在循环中被循环使用:时间局部性
- Instructions References
- 循环内部按照顺序读取指令: 空间局部性
- 循环在一段时间中持续运行: 时间局部性
从程序员的角度,在保证正确性的前提下养成良好的局部性编程习惯会很好的提升程序运行的速度。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define M 5000
#define N 5000
int sum_array_rows_1(int a[M][N]) {
int i, j, sum = 0;
for (i = 0; i < M; i++) {
for (j = 0; j < N; j++) {
sum += a[i][j];
}
}
return sum;
}
int sum_array_rows_2(int a[M][N]) {
int i, j, sum = 0;
for (j = 0; j < N; j++) {
for (i = 0; i < M; i++) {
sum += a[i][j];
}
}
return sum;
}
int main() {
static int a[M][N];
for (int i = 0; i < M; i++) {
for (int j = 0; j < N; j++) {
a[i][j] = 1;
}
}
clock_t start, end;
double cpu_time_used;
// 测试 sum_array_rows_1 (行优先 - 顺着内存走)
start = clock();
int res1 = sum_array_rows_1(a);
end = clock();
cpu_time_used = ((double)(end - start)) / CLOCKS_PER_SEC;
printf("Method 1 (Row-major) Result: %d, Time: %f seconds\n", res1,
cpu_time_used);
// 测试 sum_array_rows_2 (列优先 - 跳着内存走)
start = clock();
int res2 = sum_array_rows_2(a);
end = clock();
cpu_time_used = ((double)(end - start)) / CLOCKS_PER_SEC;
printf("Method 2 (Column-major) Result: %d, Time: %f seconds\n", res2,
cpu_time_used);
return 0;
}
Method 1 (Row-major) Result: 25000000, Time: 0.020722 seconds
Method 2 (Column-major) Result: 25000000, Time: 0.073935 seconds
从局部性的角度考虑,sum_array_rows_2 的遍历顺序和内存的顺序不一致,导致内存访问不连续,这就直接导致局部性较差,存在时间上的损失。
Memory Hierarchy
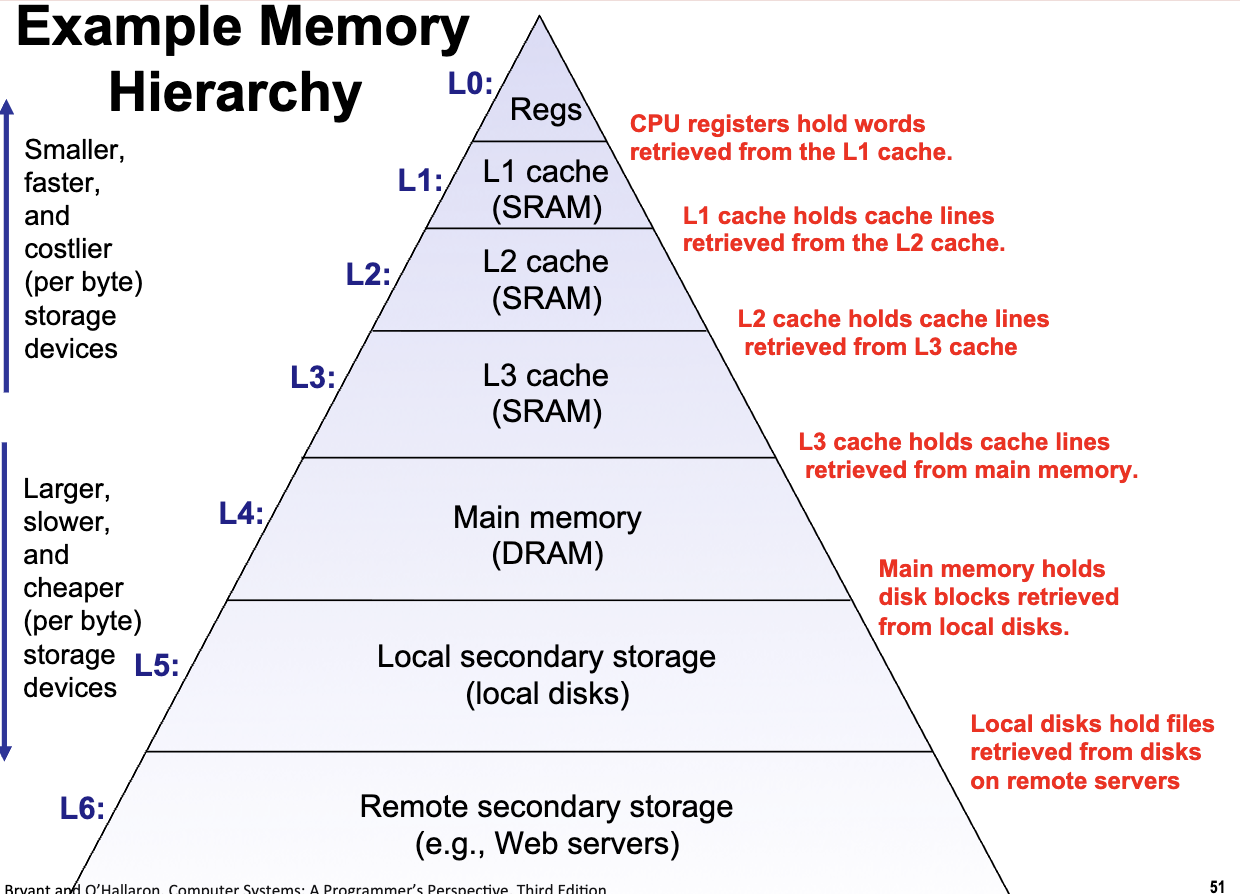
- 存储量越小,存储速度越快,价格越贵
-
存储量越大,存储速度越慢,价格越便宜
- 存储器层次结构中的每一层都包含下一层更大体量数据存储器的索引。
- For each k, the faster, smaller device at level k serves as a cache for the larger, slower device at level k+1.
Caching in Memory Hierarchy
- 狭义定义:L1, L2, L3 Cache,计算机存储结构的最上层的高速数据存储单元
- 广义定义:计算机存储结构的上一层都是下一层的缓存机制:更小但是更快
Cache works as locality!
“存储层次结构创造了一个巨大的存储池,其成本接近底部廉价存储的水平,但能以顶部高速存储的速度为程序提供数据。”
Cache line 是内存和缓存之间交换的最基本单元,当 CPU 需要读取内存中的某个数据时,如果缓存里没有(Cache Miss),缓存控制器不会只把那一个数据取回来,而是会把包含该数据在内的一整段连续内存都搬进缓存。对于 64 位的系统而言,一个 Cache line 的大小是 64 bytes (* 注意不是 8 字节!)
Cache Misses
- Cold miss: 冷启动,缓存中不存在数据
- Conflict miss: 内存中特定地址的数据只能放在特定位置的缓存块中,例如 mod (本质是一个哈希映射!),因此重复访问占据相同缓存地址的内存块会导致频繁的缓存未命中。
- Capacity miss: 缓存容量超过上限
缓存的存储是一个非常有意思的问题:
- 如何实时更新缓存?
- 如何清理不用的旧缓存?

Cache Memory Organization and Operations
直接在 CPU 旁边有 Cache Memories,使用 SRAM,存储量小,但是速度极快。
General Cache Organizations (S, E, B)
缓存的通用结构可以被视为一个三维数组:
- $S = 2^s$ sets
- $E = 2^e$ lines per set
- $B = 2^b$ bytes per cache block (the data)
因此,总缓存可以存储的字节数就是 $S \times E \times B$。
每一个 lines 中存在:
- valid bit
- tag
- 一个存储缓存数据的 Cache Block,一个 block 存储 $2^b$ 个字节的数据
Cache Read
下面介绍 Set-Associative Cache(组相联缓存) 的读取机制:当 CPU 想要从主存中寻找目标地址的数据,他会首先从缓存中读取,CPU 给出的地址被划分为:
- Set Index (s bits):特定的 Set Index
- Tag (t bits):数据标签 (t bits)
- Block Offset (b bits):如果你找到了那一整箱数据,这个偏移量告诉你具体要那一箱里的第几个字节。
具体而言,首先 CPU 会根据 Set Index 定位到特定的一个 Set 中,接着讲给定的 tag 和这个 set 中所有的 lines 中的 tag 进行比对(每一个 line 都有一个 tag!),如果 v = 1(代表当前缓存有效) 且 tag 对应,则缓存命中,接下来 Cache 就会根据 block offset 从那一行的 Data Block中取出需要的那个具体字节,送给 CPU。
缓存的 read 操作要保证尽可能精简的操作! 分块的思想
- 如果缓存没有命中,则 CPU 会从主存中读取数据,并覆盖成为新缓存。
-
CPU 从地址得到如上缓存查找的三元组是由电路的硬件设计所实现的,因此几乎没有任何计算的时间开销。
- Direct-Mapped Cache Simulation: 一种最简单的内存模拟机制,内存中的每一个块,在 Cache 中只有一个唯一固定的位置可以存放。
- 类似于一个从主存地址向缓存地址的固定哈希函数
- 会导致Thrashing,如果在局部性原理中 CPU 频繁访问的数正好映射到了相同的缓存区域 (The same block),那么这会导致大量的缓存未命中的问题,严重降低程序的运行速度
- E-way Set-Associative Cache:
- 在 E-way 结构中,E 代表每一组(Set)里有多少个行(Lines)。
- 他可以很好的解决缓存冲突的问题,因为一个 set 中存在多个独立的 blocks
- 在缓存读取的过程中,同一个 line 中不同 block 的 tag 的比较是并行实现的,因此不会带来时间上的显著开销。
- 如果没有命中,one line in set is selected for eviction and replacements.
- Replacement Policies: random, LRU
Cache Write
缓存中的值被更新后,需要实时地和内存保持同步,否则会导致数据之间的版本竞争。
- Write-through: write immediately to the memory
- Write-back: 延迟更新: 直到对应的缓存块不得不更新了,我们才进行更新!
这本质是一种 Lazy Propagations, Dirty-bit 被设为 1,并且数据不会立即写回内存中,避免多次无效的内存写入操作。并且因为缓存访问的优先级高于内存,因此 CPU 读取数据时始终会读取到更新的缓存中的数据,不会导致竞争的问题。
Multi-level Caches
- L1 Cache:
d-cache(data storage) andi-cache(instruction storage) - L2 Cache: backup for L1 Cache
- L3 Cache: unified cache, shared by all cores.(对多核场景非常友好,不同核之前共享相同的缓存)
Metrics
- Miss rate: misses/accesses
- Hit time: time to deliver a line in the cache into a processor.
- Miss Penalty: additional time required because of a miss.
因为缓存未命中的 Miss Penalty 会带来严重的性能损耗,因此任何微小的 hit rate 提升都可以带来极大的收益。
-> Writing Cache Friendly Code: 依旧是局部性原理!
Key idea: Our qualitative notion of locality is quantified through our understanding of cache memories
Performance Impact of Caches
Memory Mountains
- Read throughput: 从内存中读取的带宽
- Memory mountains: CPU 访问内存的 读取速度(吞吐量) 随 时间局部性 和 空间局部性 变化的关系。
最终画出的三维图像呈现直观的阶梯形状,展示了 L1, L2, L3 的缓存机制。
Rearranging Loops to Improve Spatial Locality
Matrix Multiplication Examples
对于每一个 C 中的元素 C[i][j],需要读取矩阵 A 的第 i 行元素和矩阵 B 的第 j 列元素,读取的两个向量做点积运算得到最终的值。
很明显,对于 A 矩阵而言,是进行的行遍历,因此局部性非常友好,但是 B 矩阵是列遍历,因此对 B 矩阵的缓存非常不友好.
Miss per inner loop iterations:
- A: 0.25 (一个 block 存储 32 字节,正好是 4 个 double)
- 因此一次缓存读取会导致后面 3 次缓存命中
- B: 1, miss every time!
因此,矩阵遍历的三层循环也有不同的遍历方式:
我们只考虑 inner loop 的缓存情况,因为我们假设矩阵的 size (n) 非常大,从时间连续性的角度考虑程序运行和缓存未命中的大部分时间都在最内层循环的遍历中。因此最后一个被循环的变量将会直接影响到 locality!
- ijk & jik: 0.25 for A, and 1.0 for B
- kij & ikj: 0 for A (
a[i][k]) 在内存循环中被循环使用, 0.25 for B, and 0.25 for C. (c[i][j], j 在最内层的循环) - jki & kji: 1.0 for A, 0 for B and 1 for C
C[i][j]的访问 i 在最内层,每次都缓存未命中B[k][j]has good localityA[i][k]miss every time!
Overall:
\[C[i][j] = \sum_k A[i][k] \times B[k][j]\]j 应该作为 inner loop 的循环变量,这样不会存在频繁缓存未被命中的情况
当然,我们也通过一个小批量的实验验证了这样的结果:
#include <stdio.h>
#include <stdlib.h>
#include <sys/time.h>
#include <time.h>
// Matrix structure definition
typedef struct {
int rows;
int cols;
double* data;
} Matrix;
// Create a matrix with specified dimensions
Matrix* create_matrix(int rows, int cols) {
Matrix* mat = (Matrix*)malloc(sizeof(Matrix));
if (mat == NULL) {
printf("Failed to allocate memory for matrix structure\n");
return NULL;
}
mat->rows = rows;
mat->cols = cols;
mat->data = (double*)malloc(rows * cols * sizeof(double));
if (mat->data == NULL) {
printf("Failed to allocate memory for matrix data\n");
free(mat);
return NULL;
}
return mat;
}
// Free matrix memory
void free_matrix(Matrix* mat) {
if (mat != NULL) {
if (mat->data != NULL) {
free(mat->data);
}
free(mat);
}
}
// Initialize matrix with random values
void init_matrix_random(Matrix* mat) {
srand(time(NULL));
for (int i = 0; i < mat->rows * mat->cols; i++) {
mat->data[i] = (double)(rand() % 100) / 10.0;
}
}
// Initialize matrix with fixed values
void init_matrix_fixed(Matrix* mat, double value) {
for (int i = 0; i < mat->rows * mat->cols; i++) {
mat->data[i] = value;
}
}
// Print matrix content (only for small matrices)
void print_matrix(const Matrix* mat) {
for (int i = 0; i < mat->rows; i++) {
for (int j = 0; j < mat->cols; j++) {
printf("%8.2f ", mat->data[i * mat->cols + j]);
}
printf("\n");
}
}
// Get current time in milliseconds
double get_time_ms() {
struct timeval tv;
gettimeofday(&tv, NULL);
return tv.tv_sec * 1000.0 + tv.tv_usec / 1000.0;
}
// Matrix multiplication using i-j-k loop order
Matrix* matrix_multiply_ijk(const Matrix* A, const Matrix* B) {
if (A->cols != B->rows) {
printf("Error: Matrix dimensions mismatch!\n");
return NULL;
}
Matrix* C = create_matrix(A->rows, B->cols);
if (C == NULL) return NULL;
// Initialize to zero
for (int i = 0; i < C->rows * C->cols; i++) {
C->data[i] = 0.0;
}
// i-j-k loop order
for (int i = 0; i < A->rows; i++) {
for (int j = 0; j < B->cols; j++) {
for (int k = 0; k < A->cols; k++) {
C->data[i * C->cols + j] +=
A->data[i * A->cols + k] * B->data[k * B->cols + j];
}
}
}
return C;
}
// Matrix multiplication using k-i-j loop order
Matrix* matrix_multiply_kij(const Matrix* A, const Matrix* B) {
if (A->cols != B->rows) {
printf("Error: Matrix dimensions mismatch!\n");
return NULL;
}
Matrix* C = create_matrix(A->rows, B->cols);
if (C == NULL) return NULL;
// Initialize to zero
for (int i = 0; i < C->rows * C->cols; i++) {
C->data[i] = 0.0;
}
// k-i-j loop order
for (int k = 0; k < A->cols; k++) {
for (int i = 0; i < A->rows; i++) {
for (int j = 0; j < B->cols; j++) {
C->data[i * C->cols + j] +=
A->data[i * A->cols + k] * B->data[k * B->cols + j];
}
}
}
return C;
}
// Matrix multiplication using j-k-i loop order
Matrix* matrix_multiply_jki(const Matrix* A, const Matrix* B) {
if (A->cols != B->rows) {
printf("Error: Matrix dimensions mismatch!\n");
return NULL;
}
Matrix* C = create_matrix(A->rows, B->cols);
if (C == NULL) return NULL;
// Initialize to zero
for (int i = 0; i < C->rows * C->cols; i++) {
C->data[i] = 0.0;
}
// j-k-i loop order
for (int j = 0; j < B->cols; j++) {
for (int k = 0; k < A->cols; k++) {
for (int i = 0; i < A->rows; i++) {
C->data[i * C->cols + j] +=
A->data[i * A->cols + k] * B->data[k * B->cols + j];
}
}
}
return C;
}
// Test matrix multiplication with timing
void test_multiplication(const char* name, Matrix* (*multiply_func)(const Matrix*, const Matrix*),
Matrix* A, Matrix* B) {
printf("\nTesting %s...\n", name);
double start_time = get_time_ms();
Matrix* C = multiply_func(A, B);
double end_time = get_time_ms();
if (C != NULL) {
printf("Time: %.2f ms\n", end_time - start_time);
free_matrix(C);
} else {
printf("Multiplication failed!\n");
}
}
int main() {
const int SIZE = 2000;
printf("Creating %dx%d matrices...\n", SIZE, SIZE);
printf("Memory required per matrix: %.2f MB\n", (double)(SIZE * SIZE * sizeof(double)) / (1024 * 1024));
double start_time = get_time_ms();
// Create large matrices
Matrix* A = create_matrix(SIZE, SIZE);
if (A == NULL) {
printf("Failed to create matrix A\n");
return 1;
}
Matrix* B = create_matrix(SIZE, SIZE);
if (B == NULL) {
printf("Failed to create matrix B\n");
free_matrix(A);
return 1;
}
double init_time = get_time_ms();
// Initialize matrices with fixed values for consistency
printf("Initializing matrices...\n");
init_matrix_fixed(A, 1.0);
init_matrix_fixed(B, 2.0);
double ready_time = get_time_ms();
printf("Initialization time: %.2f ms\n", ready_time - init_time);
printf("Total preparation time: %.2f ms\n", ready_time - start_time);
// Test different loop orders
printf("\n========================================");
printf("\nMatrix Multiplication Performance Test");
printf("\nMatrix size: %dx%d", SIZE, SIZE);
printf("\n========================================");
test_multiplication("i-j-k loop order", matrix_multiply_ijk, A, B);
test_multiplication("k-i-j loop order", matrix_multiply_kij, A, B);
test_multiplication("j-k-i loop order", matrix_multiply_jki, A, B);
printf("\n========================================\n");
// Clean up
printf("Cleaning up memory...\n");
free_matrix(A);
free_matrix(B);
printf("Test completed!\n");
return 0;
}
Memory required per matrix: 30.52 MB
Initializing matrices...
Initialization time: 31.14 ms
Total preparation time: 31.15 ms
========================================
Matrix Multiplication Performance Test
Matrix size: 2000x2000
========================================
Testing i-j-k loop order...
Time: 20238.65 ms
Testing k-i-j loop order...
Time: 18889.86 ms
Testing j-k-i loop order...
Time: 63872.44 ms
========================================
Cleaning up memory...
Test completed!
在一个 2000 * 2000 的 double 类型的矩阵上,k-i-j 的计算方式在相同算法的前提下比 i-j-k 获得了更快的速度,并且我们看到缓存不友好的算法 (j-k-i 遍历方式) 严重拖慢了矩阵乘法的计算速度。
当然,这只是一个非常简单的缓存演示实验
Using Blocking to Improve temporal Locality
在上文的矩阵乘法的演示中我们看到,大矩阵的运算因为缓存容量的限制,会导致缓存未命中的事情频繁发生。我们希望:一个数据一旦进入缓存,系统尽可能运算这个数据,提升缓存命中率.
Blocking: 通过将大数据集切分成小块(Blocking)来处理,确保数据在被移出高速缓存之前被多次重复使用,从而减少访问慢速主内存的次数,提高程序运行速度。例如上文矩阵乘法的速度,矩阵分块乘法可以很好地利用 spatial locality 的思想,优化空间局部性:
// Blocked matrix multiplication for better cache utilization
Matrix* matrix_multiply_blocked(const Matrix* A, const Matrix* B) {
if (A->cols != B->rows) {
printf("Error: Matrix dimensions mismatch!\n");
return NULL;
}
Matrix* C = create_matrix(A->rows, B->cols);
if (C == NULL) return NULL;
// Initialize to zero
for (int i = 0; i < C->rows * C->cols; i++) {
C->data[i] = 0.0;
}
// Blocked matrix multiplication
// Outer loops iterate over blocks
for (int ii = 0; ii < A->rows; ii += BLOCK_SIZE) {
for (int jj = 0; jj < B->cols; jj += BLOCK_SIZE) {
for (int kk = 0; kk < A->cols; kk += BLOCK_SIZE) {
// Inner loops iterate within each block
int i_end = (ii + BLOCK_SIZE) < A->rows ? (ii + BLOCK_SIZE) : A->rows;
int j_end = (jj + BLOCK_SIZE) < B->cols ? (jj + BLOCK_SIZE) : B->cols;
int k_end = (kk + BLOCK_SIZE) < A->cols ? (kk + BLOCK_SIZE) : A->cols;
for (int i = ii; i < i_end; i++) {
for (int k = kk; k < k_end; k++) {
for (int j = jj; j < j_end; j++) {
C->data[i * C->cols + j] +=
A->data[i * A->cols + k] * B->data[k * B->cols + j];
}
}
}
}
}
}
return C;
}
========================================
Matrix Multiplication Performance Test
Matrix size: 2000x2000
========================================
Testing Blocked multiplication...
Time: 16964.33 ms
可以看到,分块矩阵乘法通过优化空间局部性,极大提升了矩阵运算的速度!